vonoroi keycaps
2026-07-04
Found a little gem on Reddit.

Found a little gem on Reddit.
I been toying with a tiny game made with PICO-8. You can play it below.
Few fun facts about it.
You can also download the cartridge if you want to play on your own device locally.
Lucide is a fantastic resource for icons. Just wanted to make a note for myself because I keep forgetting the name.
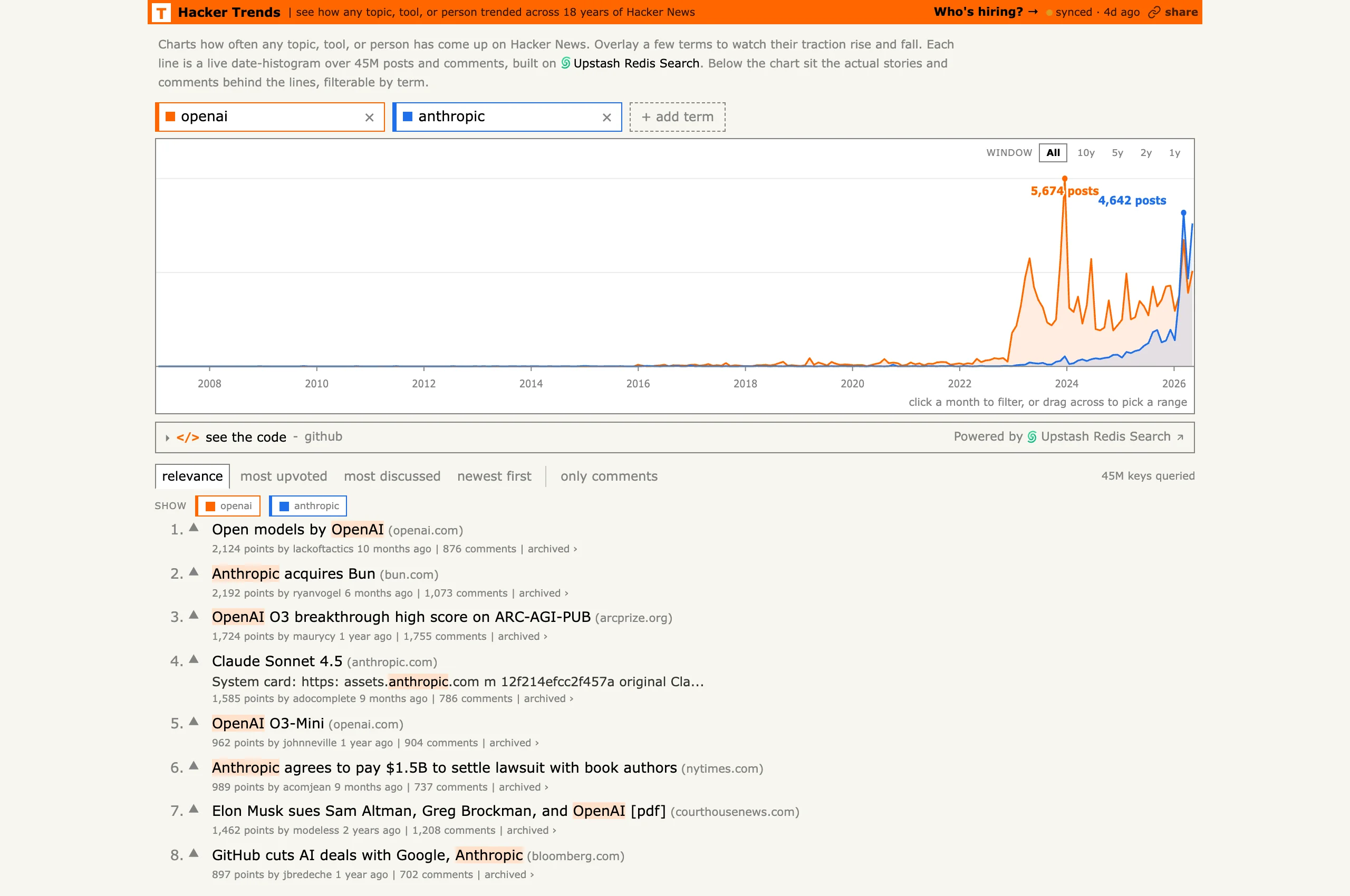
Someone made Google Trends for Hacker News by indexing 18 years of comments. The tool lives at hackernewstrends.com and lets you overlay how often terms show up over time. Mostly bookmarking this for myself, but it's a fun way to confirm hunches about when a topic actually took off.
A Billboard chart headline made the rounds: "Olivia Rodrigo becomes the first woman in history to debut her first ten top 10 Hot 100 hits in the top 10."
Lynn quote-posted it a theorem that certainly made me giggle.
A hit song on the Billboard 100 charts is termed $k$-good if it is ever in a weekly top-$k$, and $k$-immediate if it debuts in the top-$k$. An artist is $(n,k)$-Olivian if their $n$ first $k$-good hits are all also $k$-immediate.
Headline 1. Olivia Rodrigo is the first $(10,10)$-Olivian woman.
I made this YouTube video the other day about how all code, eventually, is abandoned. It doesn't die, because it still exists, but it simply won't have people working on it anymore.
But there's one thing that can prevent it, the code can graduate! It can be that you had an idea so useful that another project, a much larger one, will grab it to run with it.
It's happened twice to me. A few widgets from wigglystuff just got ported to marimo just like how a few scikit-lego components (or at least their spirit) have found their way into scikit-learn.
I wish it could happen to more people because this kind of pollination across projects is exactly what keeps the creativity alive.
I work with YouTube for my job and I'm happy to announce that I found a remedy for the extremely distracting landing page. It's a Chrome extension called redirector that lets you add redirect rules to the browser by hand.
Whenever you'd go to the YouTube landing page it'll redirect you to another page. In my case, I make it go to my YouTube subscriptions. Those are way less distracting and typically show me stuff that I've already seen anyway. Much better!
Been thinking about a quote lately. The quote is from the final episode of the first season of Shell Game, which is a great podcast.
As far back as 2013, a team of engineers at YouTube hit upon a phenomenon it called “the inversion”: the point at which the fake content we encounter on the internet outstrips the real. The engineers were developing algorithms to distinguish between authentic human views and manufactured web traffic — bought-and-paid-for views from bots or “click farms.” Like the discriminator in a GAN, the team’s algorithms studied the traffic data and tried to understand the difference between normal visitors and bogus ones.
Blake Livingston, an engineer who led the team at the time, told me the algorithm was working from a key assumption: “that the majority of traffic was normal.” But sometime in 2013, the YouTube engineers realized bot traffic was growing so rapidly that it could soon surpass the human views. When it did, the team’s algorithm might flip and start identifying the bot traffic as real and the human traffic as fake.
Part of why it is in my mind is because it's something to worry about, but it's also an epic nerd snipe for the algorithm designer part of my brain. You need a new breed of algorithm. Not quite classifier, not quite outlier detector and not quite clusterer. Something new.
From this interview I learned about the marketing around Niche. What's interesting here isn't just how the game got developed but also how it eventually got marketed.
It's an indie game and these kinds of games are usually promoted by going to the video gaming YouTubers and getting them to demo/talk about it. This particular game is about genetics though, so the team also reached out to some science channels.
They should be happy they did because it actually turned out that science/education YouTube channels picked it up way more. It also makes some sense when you think about it. There are so many video games out there that the video game YouTubers get to be picky. But those that do science/genetics may not only be more receptive to over it, they will also likely have an audience that the other channels may never reach. Double win!
Feels like a nice marketing reminder. There's usually more than one niche that you can try to appeal to. And the less obvious ones might end up being more meaningful.


{kind=link}