Gaussian Auto Embeddings
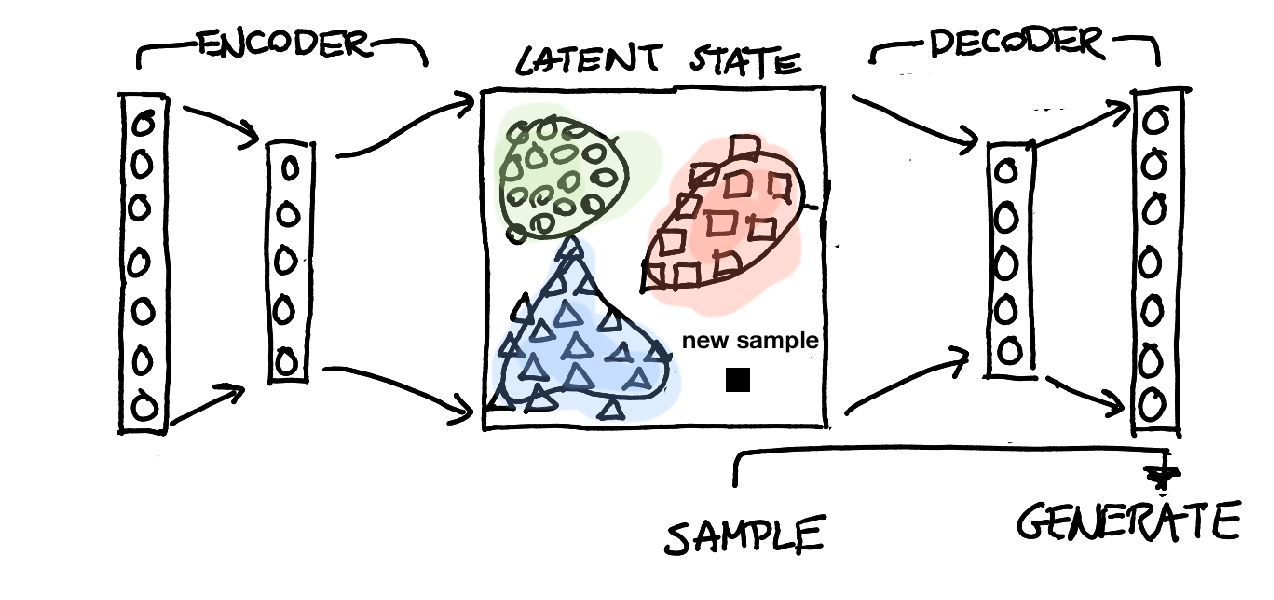
Below is a picture of a simple autoencoder.
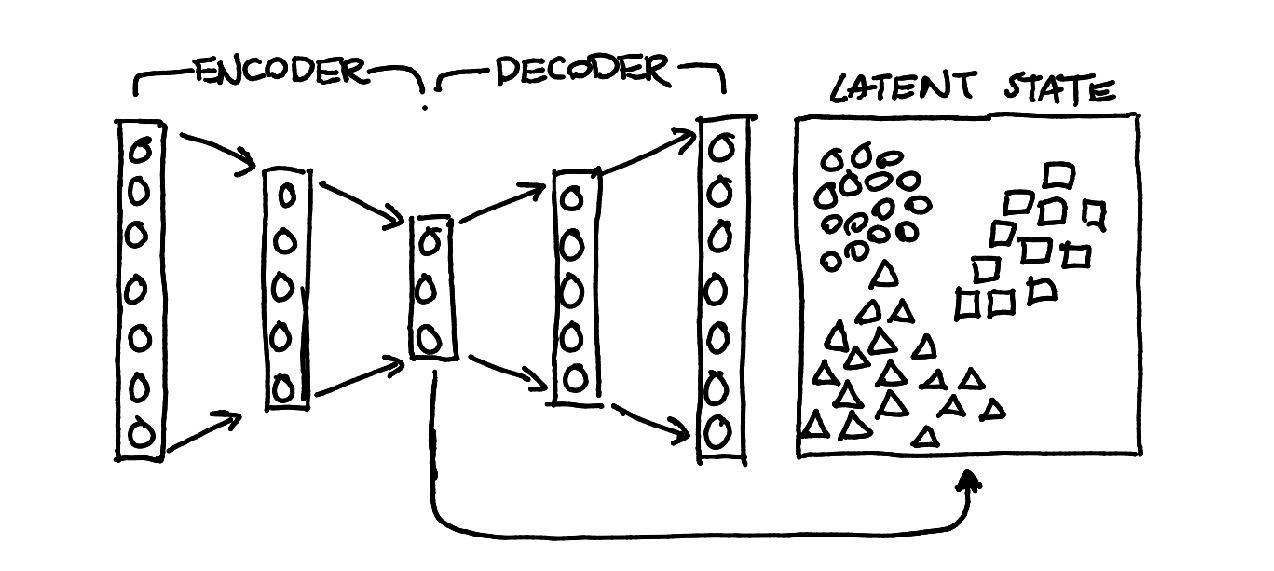
If we train this autoencoder appropriately then we can assume that we gain a latent representation of our original data. This can be done via convolution layers, dense layers or hyped layers. It doesn't really matter as long as we're confident that the encoder can decode whatever it encodes.
It is worthwhile to note that this encoder is trained in a completely unsupervised manner. It often can be the case, like in mnist, that clusters of similar items appear. This gave me an interesting thought: we can also train a model on this latent representation. This way we can see the encoder as a mere preprocessing step.
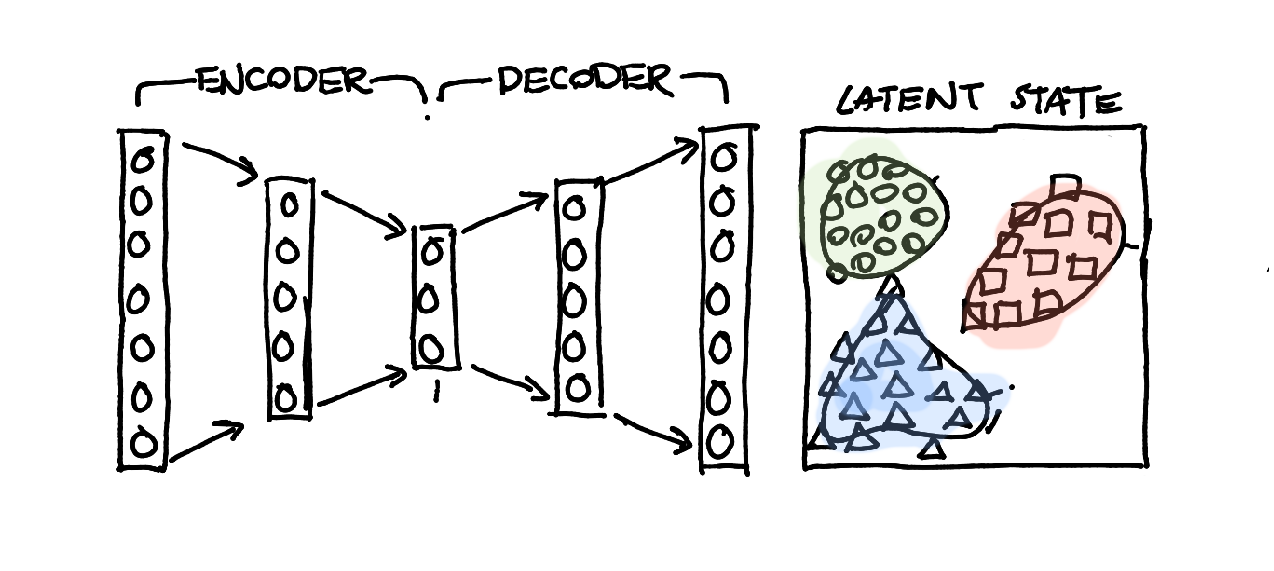
I started thinking some more. I could do an extra step and assume that the model I'd want to train is a gaussian mixture model. I'd train a single gaussian mixture model per class. If I do that then there's a few things that I gain:
- I can use the GMM models as a classifier. When a new datapoint comes in then I can push it through the encoder and check the resulting likelihood for every GMM class. I could pick the GMM with the highest likelihood or report on normalised likelihoods as a probability vector.
- I can also suggest that a new datapoint does not belong to any class. I can put a threshold on the likelihoods of each GMM which could lead to a 'none' prediction. This is nice.
- I can also sample from each GMM with ease (because, it's gaussian). The sample that I get in latent space can be thrown in the decoder and this might be a nice method to sample data (like GANs and VAEs).
- I can interpret the GMM as a manifold of sorts. The GMM can describe a somewhat complicated shape in latent space that belongs to a certain class.
- Because the GMMs are all gaussian, I gain some articulate properties from the model. I can calculate the entropy per GMM and I can calulate the KL divergence between them. I can quantify an estimate of how similar or dissimilar classes are.
With all this in mind. It feels more appropriate to draw this model like this:
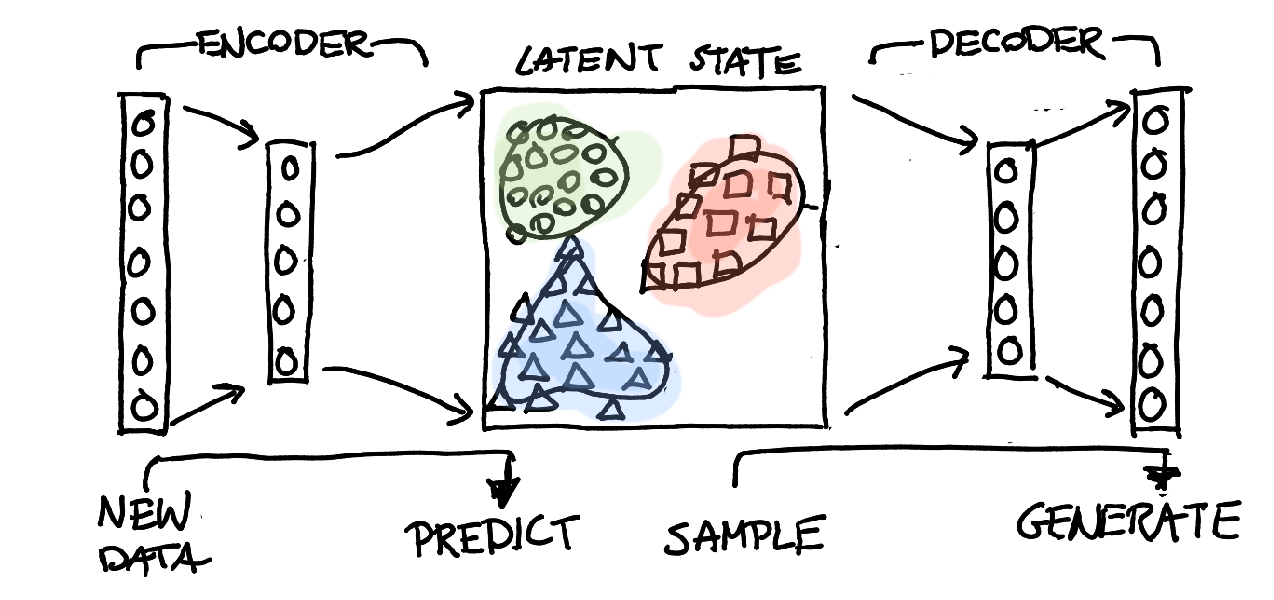
This could be a somewhat general, albeit very articulate model. This is nice most neural approaches aren't too great in the explanatory department.
But does it work?
Let's see if we can get a view into this. I've got two notebooks that can back me up; one with mnist as a dataset and one with fashion mnist as a dataset. I'm well aware that this won't be a general proof, but it seems to be a nice place to start.
Autoencoder
The data that goes into the encoder, also seems to come out.
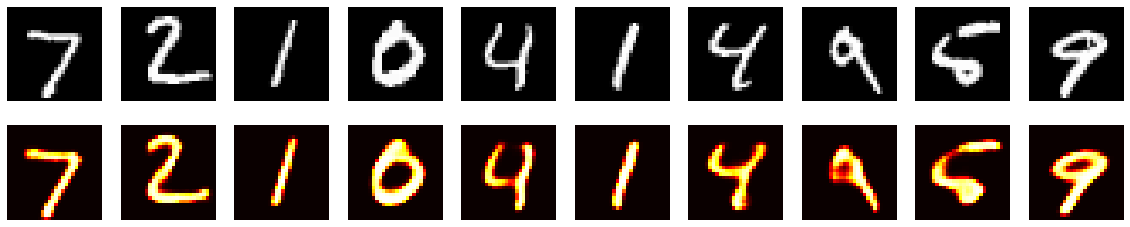
The white pixels go in, the bright colors go out. It works!
Sampling Data
I've trained simple autoencoders as well as gaussian mixture models per class. This is what you see what I sample from a gaussian for a given class and then pass that along the decoder.

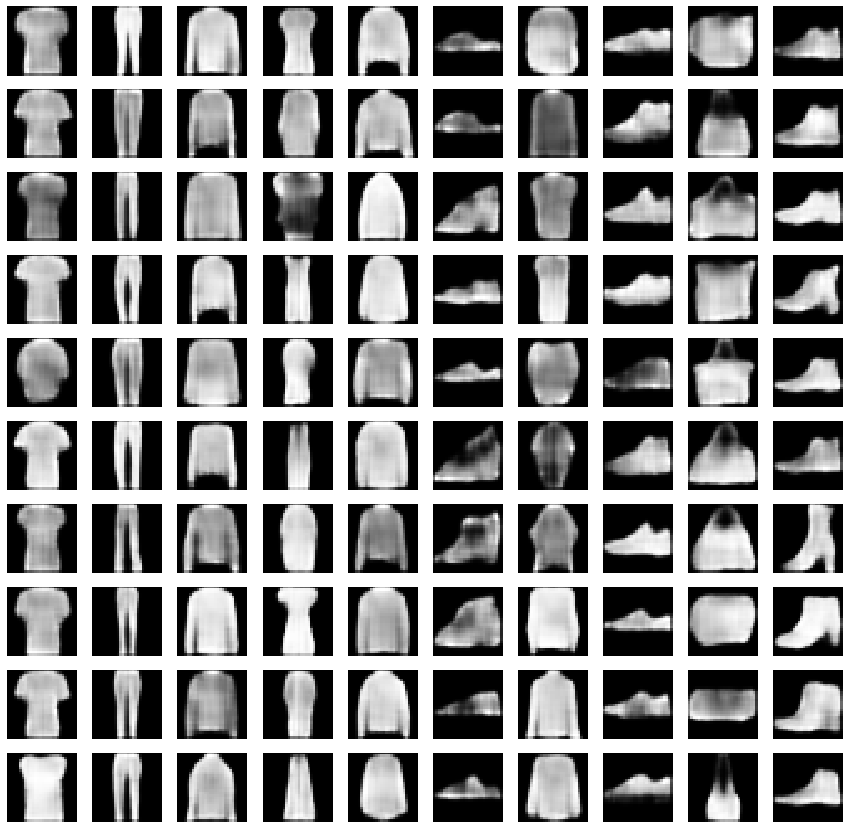
The numbers look like numbers, the fashion looks like fashion!
It looks allright, not perfect, but allright. There's very little tuning that I did and I didn't train for more than 60 epochs. Definately the autoencoder might appreciate a bit more network design, but overall it seems to work.
You can also train a single GMM on all classes instead of training a GMM per class. If you sample from this single GMM then it looks sensible, but worse.


We loose some context, but it still feels like we're surfing on a manifold.
Manifold Evidence
Suppose that I do not sample from the GMM but that I sample uniformly the entire latent space.
When I do that, the decoder outputs gibberish. What you mainly see is that some upsampling layers randomly start to activate and propogate forward.


The left side shows output from the mnist decoder, the right side shows output from the fashion mnist decoder.
This shows that my approach is a bit different than perhaps how some VAEs might do it. Since my method does not impose and form of variational shape during the embedding step the points in latent space might enjoy a bit more freedom to place themselves in the space however they like. This means that the latent space will have some useless areas and it is the hope that the GMM's that I train will never assign any likelihood there.
Predicting Data
You can sample actual labels and put them into a GMM to check the likelihood that comes out.
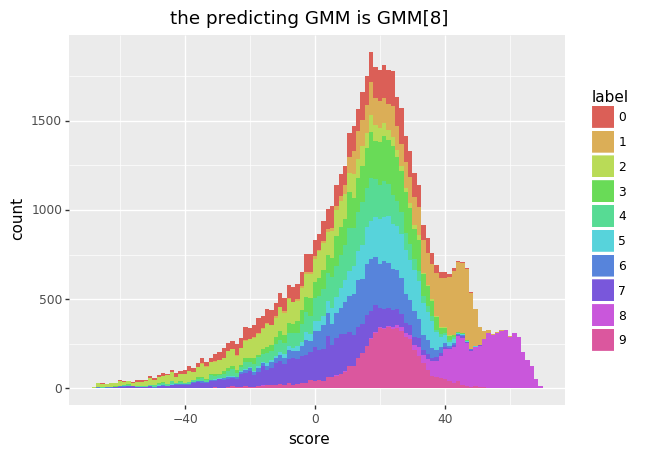
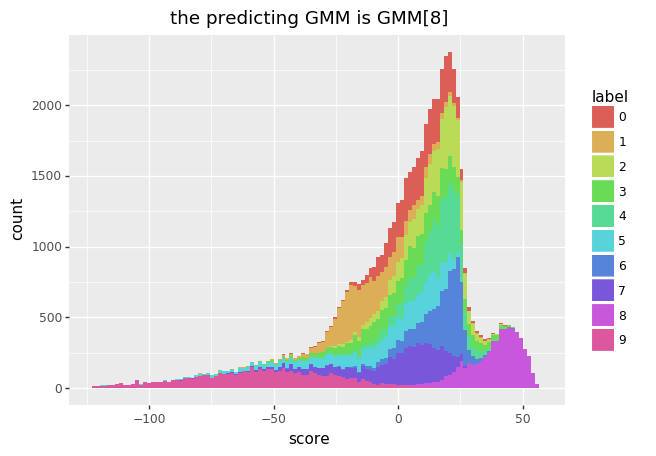
The accuracy on the test/train sets are describe in the table below.
mnist train 0.9816
mnist test 0.9766
fmnist train 0.8776
fmnist test 0.8538
Not the best, but not the worst either.
Transitioning Classes
When I sample one point from one GMM class and another point from another then I can try to see what it looks like to morph an item from one class to another. What do I mean by this? I mean that we won't merely transition between images like below.
Instead what I do is sample two classes in latent state and interpolate in latent state before passing it on to the decoder.

These look allright, but they could be better, you could for example sample two classes that are hard to morph.

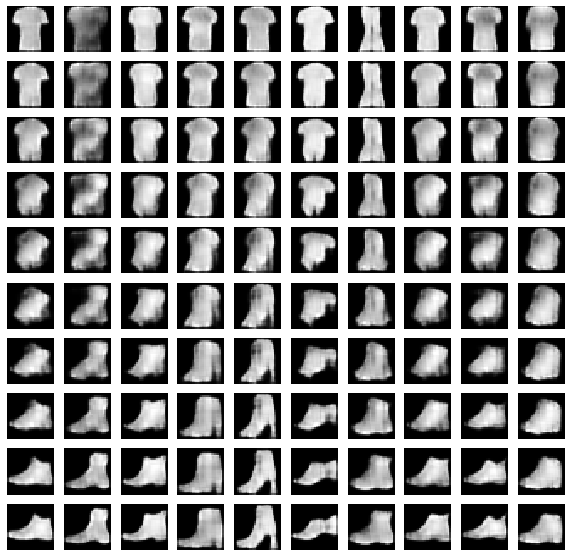
Maybe it is hard to traverse the manifold between a shoe and a shirt.
Articulating Styles
I've trained the GMMs with 6 means. It seems that every mean is able to pick up on a certain cluster within a class. One interpretation is style. There are different styles of writing a number just like there are multiple styles of drawing a piece of clothing.

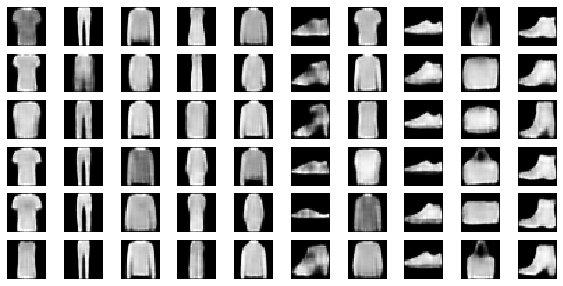
Six styles are shown because the GMM has this setting.
What doesn't work well
There's some tricky bits with this approach.
- It's arguably a benefit that the latent state is generated from an unsupervised approach because there is less label bias to overfit on. But we do get a two stage approach and it might be possible to come up with better embeddings if we could create a loss functions to combine the GMM output as well as the autoencoder.
- I am using GMMs because they are general, but they are not perfect. There may very well be embeddings that won't fit very well.
- If the autoencoder is trained poorly then we shouldn't expect much from the gaussians in the middle either. We're still stuck with training an autoencoder that can be very complex in layers and hyperparameters.
- However flexible, the GMMs also need hyperparameter tuning, which can be expensive to do well.
- The bigger the latent state, the easier it will be for the autoencoder. The smaller the latent state, the easier it will be for the GMM. This is a nuisance.
!!! quote "Appendix"
I should try this problem on a harder problem, but sofar I'm pretty happy with the results. There's some things I can do to make the transitions between the classes better but thats something for another day.
It is very liberating to use python tools like lego piecies, which is exactly what I've been doing here. Put a encoder here, place a gaussian there ... the experimentation is liberating. It's never been easier to do this.
But the reason I was able to get here was because I didn't feel like implementing a popular algorithm. Rather, I wanted to have an attempt at doing some thinking on my own. I see a lot of people skip this mental step in favor of a doing something hip.
Maybe, just maybe, a lot of folks are doing themselves short by doing this. I may have stumbled apon something useful for a project here and I wouldn't have gotten here if I would just blindly follow the orders of an academic article.
Maybe folks should do this more often.
There are two notebooks that contain all code. One with [mnist data](https://colab.research.google.com/drive/1_QoyyP6nQgPm_VbXkl0gqI5yQn8j31t_) and [fashion mnist data](https://colab.research.google.com/drive/1r6OobB-yyY3Q18Hlql0KkEDYKOqaci_l). Feel free to play with them and let me know if I've made horrible errors.