poke2vec
I read a surprisingly good paper the other day. One that involves making word embeddings for Pokemon. It understand that it might sound like a meme but I genuinely think the authors did something interesting here.

The Task
The authors were trying to find descriptive adjectives for Pokemon. From my end this is pretty interesting/non-abritrary for a few reasons;
- Pikachu is yellow. That's obvious. But because it's obvious, you may wonder if there's any text out there to even mention it. If no text mentions it, how may you learn it as a pattern?
- It's plausible that this domain is too niche for most pretrained embedding models. Do you need to train your own? On what data might you do that? Subtitles?
The Approach
To find the adjectives the authors ended up scraping fan fiction for their experiment. They ended up using 2.3 Gb of fanfiction to train their own embeddings which they've also open-sourced.
To quote the paper:
In order to rank Pokemon properties, we crawl a larger corpus of texts written about Pokemon. Many Wikipedia-like sources are too neutral to reveal anything meaningful about Pokemon, Pokedex entries are usually too short and nondescriptive for our needs. Subtitles form the Pokemon TV show come with their own problem of audio-visual grounding of the text. Fortunately, we found a great resource of stories authored by Pok´emon fans called Fanfiction
They tried a bunch of approaches, some of which are summarised in the table below.
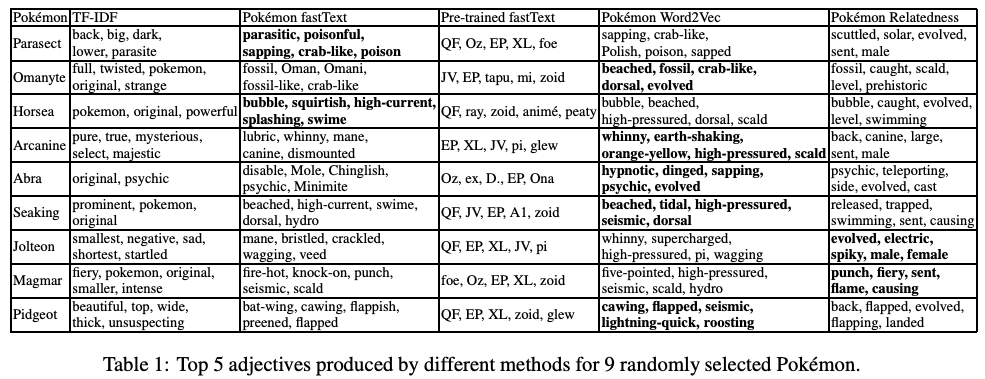
The Lesson
So what did the authors learn? Something that applies to a lot of tasks! To quote their conclusion:
Based on our research, we can conclude that the pretrained models do not work with Pokemon at all. Clearly, Pokemon itself is by no means so deviant a phenomenon that it could not be modeled with word embeddings. The problem we can see is part of a wider phenomenon that has received a little attention in the field of NLP. If pretrained models, which are constantly used in various NLP studies, are not able to describe Pokemon, what other phenomena might they describe equally poorly? In general, our discipline does not pay very much attention to how well computational models work when applied to a completely new context.
It confirms one of my beliefs: it may make sense to train your own embeddings instead of hoping that the general embeddings from Wikipedia will aid in a specific domain.
Related: most domains are specific.