
In the beginning of this year I noticed a press release from Boston Consulting Group. It seems they have an analytics group called BCG Gamma which released a new scikit-learn compatible tool called FACET. To quote the capitalized headline, it's a tool that helps you "Understand Advanced Machine Learning Models So They Can Make Better and More Ethical Decisions".

I've done some open-source work in the area of algorithmic fairness so I was immediately curious. I went to the documentation page to have a look. By looking around I learned it was a package that offers a lot of visualisation tools, some of which were inspired by Shapley values.
Unfortunately, between all of these interpretability charts there was a big red flag.
load_boston
The main tutorial on the documentation page was using a dataset from scikit-learn
know as the load_boston dataset. The goal of the dataset is to predict house prices and it
is commonly used as an example on what machine learning can do.
You can read more about the dataset on the API documentation
and in the user guide.
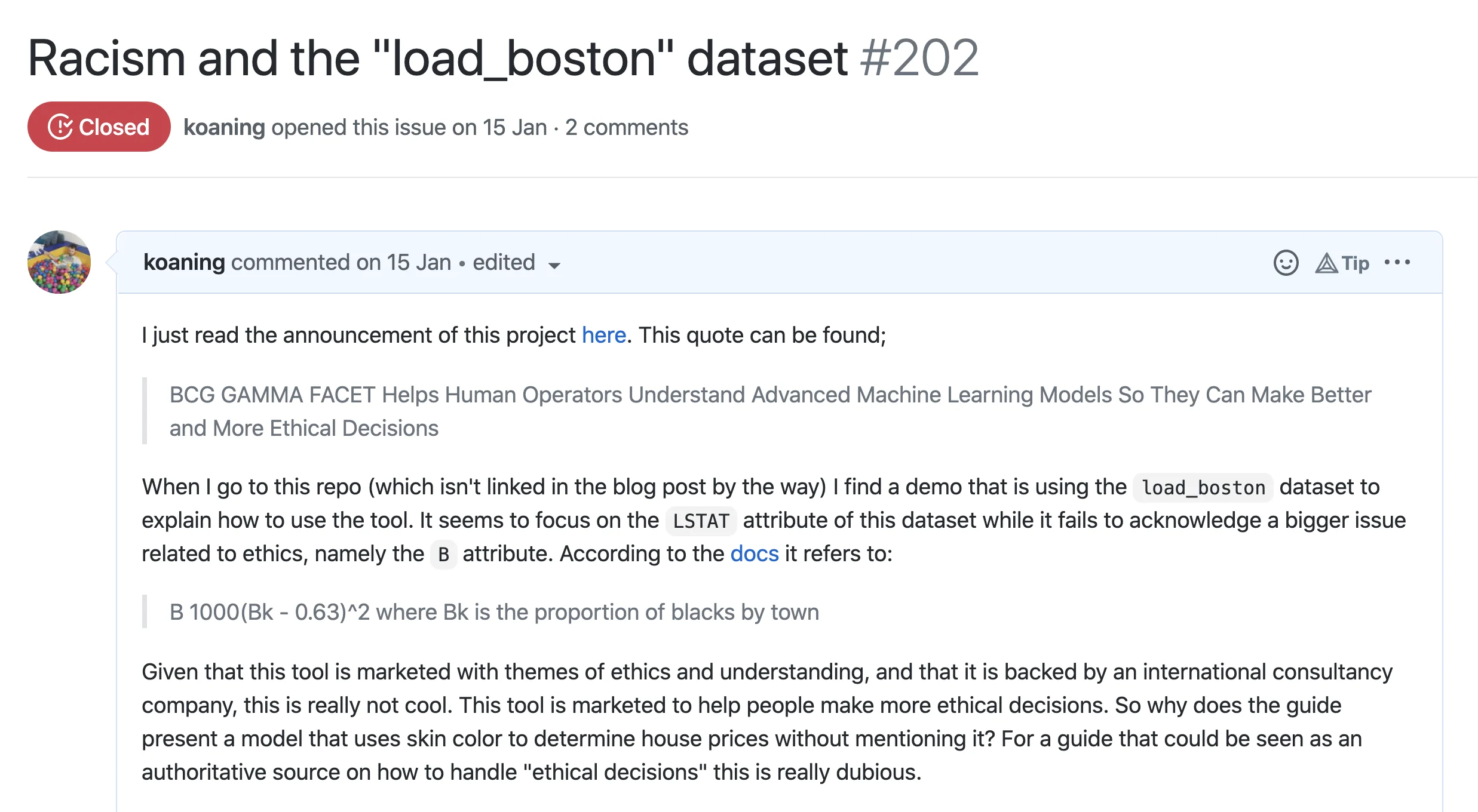
This dataset is notorious because of one variable that is in that dataset.
> print(load_boston()['DESCR'])
...
- B 1000(Bk - 0.63)^2 where Bk is the proportion of blacks by town
I remember being shocked when I first realised that scikit-learn was hosting a dataset that uses skin color to predict a house price. Did nobody else notice? It's what made me start learning more about algorithmic fairness and it led to this scikit-learn transformer and this popular talk. There's a deeper story behind this parameter worth reading too.
At any rate, it's clearly inappropriate. So I figured I'd do the right thing by notifying the maintainers on GitHub and asking them to replace the tutorial.
To anybody curious, yes, the dataset is up for removal from scikit-learn too. It's a pretty big effort too because many tutorials need an update.
I want to acknowledge that the group responded swiftly and they fixed their documentation within a day. That said, this is the perfect example of a growing concern on my end.
Ouch
The painful part isn't just that this dataset was used on a documentation page. The issue is that this page will be seen as an authoritative source on how to properly "do the fairness thing". It shows you how to use the tricks of the package, but it omits the need to understand the data before you even try to model it.
And here's the scary part: we're not talking about a hobby project here. Facet is actively promoted by the Boston Consultancy Group, a strategy consultancy firm with a global reach. One can expect this tool to be promoted and used by a lot of their clients. Imagine the harm that can be done if people start considering their algorithms "fair" or "ethical" merely because they're using a package.
Naive Bias[tm]
The problem in the tutorial isn't that the visualisation techniques can't be applied in a meaningful way for fairness. It's that the technique seems to have been distracting from the actual problem in the dataset. And it's that what worries me.
There's a lot of noble work to be done in the realm of fairness tooling and it's an area that certainly deserves plenty of attention. But I fear it's attracting a wrong attitude. We can try to make the model more constrained, more monotonic, more bayesian, with more Shapley values or more causal ... but that alone won't "solve fairness" in any meaningful sense.
It'd be a true shame if people consider a python library as a checkbox so that they no longer need to think about the information that is hidden in their data.
It Pops Up a Lot
What doesn't help is that this isn't the only documentation page with this issue.
A few months after the FACET mishap I found myself on the
causalnex repository. This is a project from QuantumBlack,
which is the advanced analytics group part of McKinsey. Also here,
there was a suggestion that causal models might be able to make the world more fair.
Also here, we're talking about a company with a global reach. Also here,
the documentation page was using the load_boston dataset. Therefore, also here,
I opened a GitHub issue.
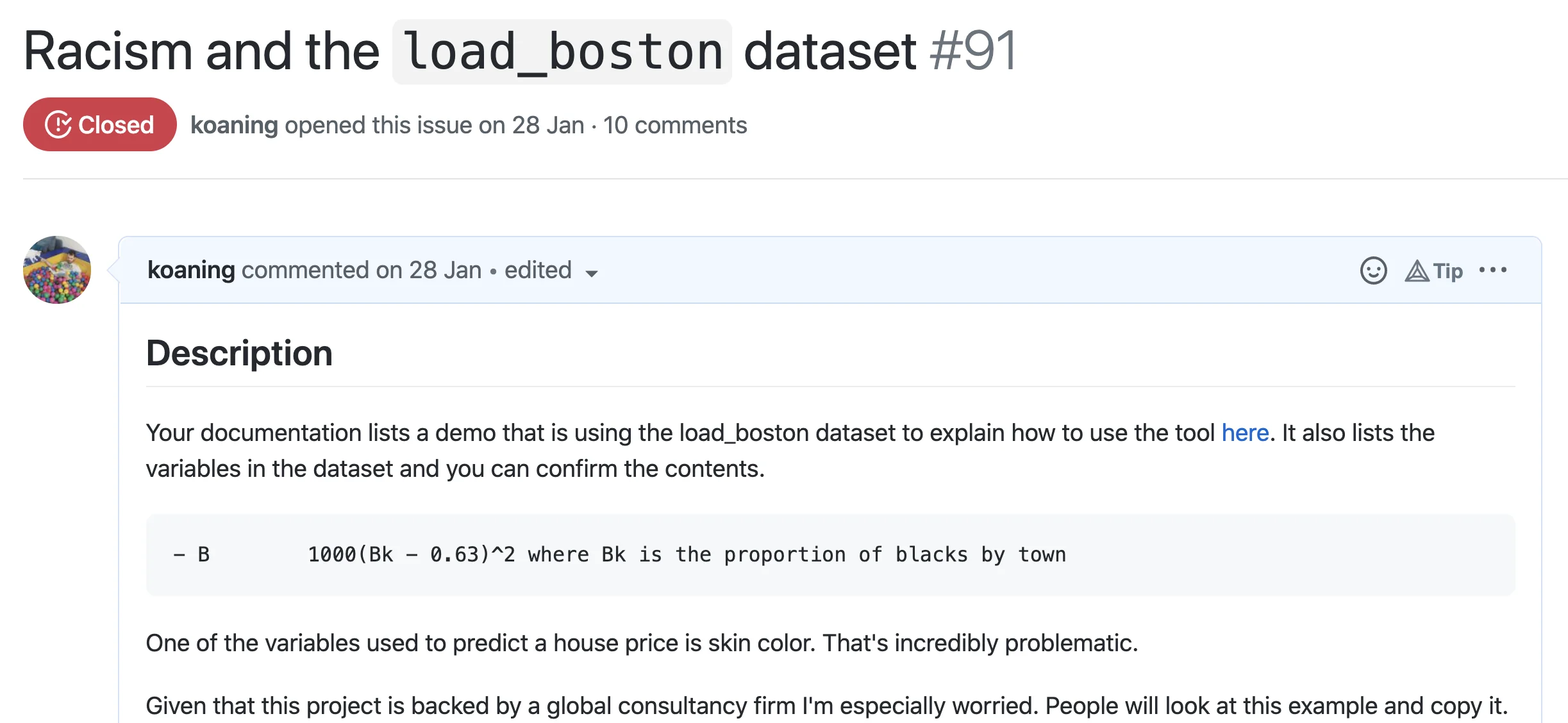
I want to give the causalnex group credit where credit is due because they too immediately recognized the issue and started replacing their example. This group even invited me to speak and make my concerns clear to the maintainers of the project. They're even taking the effort of adding data-cards to all of their examples. But the concern remains; we may be in for a wave of fairness tools that, albeit with best intentions, will distract us from reality.
It's not just the load_boston dataset that has me concerned though. There's a
whole zoo of datasets that deserve explicit acknowledgement of their bias.
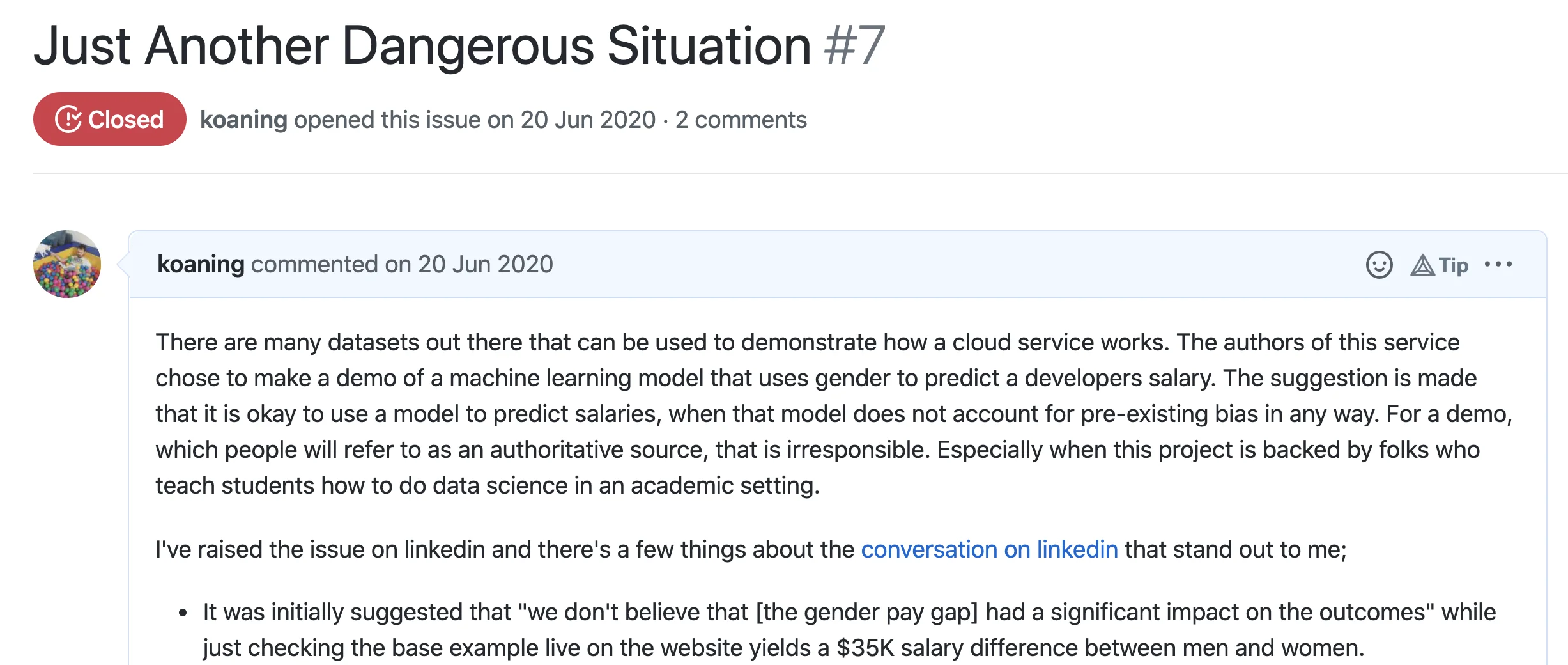
The launching demo of Scailable, a Dutch startup that
wants to web-assebmle all the machine learning models, had a demo that used the adult dataset.
This dataset allows you to train a model to predict the salary of an employee.
Unfortunately, gender is one of the variables used to make the prediction.
The painful part here wasn't just that members of the group initially though it was fine because they had a small disclaimer on the page. Rather, it was that the founding members of the group all teach data science in Dutch universities. So again we're talking about a document that will be seen as an authoritative source on how to construct machine learning algorithms. Again, I felt compelled to write a GitHub issue.
They, too, have since updated their docs and they have also acknowledged they should've picked another demo. They also wrote a manifesto.
Here and Now
I fear we're going to be in for a wave for fairness tools that are incentivised by marketing goals. They may be made with the best intentions but, as the examples show, are just tools that are at risk of distracting us from more meaningful tasks.
The fairlearn project does a much better job in setting expectations. On their landing page it's pointed out that "fairness is sociotechnical". Here's an excerpt from their section:
Fairness of AI systems is about more than simply running lines of code. In each use case, both societal and technical aspects shape who might be harmed by AI systems and how. There are many complex sources of unfairness and a variety of societal and technical processes for mitigation, not just the mitigation algorithms in our library. Throughout this website, you can find resources on how to think about fairness as sociotechnical, and how to use Fairlearn's metrics and algorithms while considering the AI system's broader societal context.
Compare this to: Understand Advanced Machine Learning Models So They Can Make Better and More Ethical Decisions
Where to go from here?
It's been a few months now and during a morning walk I was contemplating how these documentation mishaps could have occurred. After mulling on it, the thing that strikes me with all these examples is that all the errors on the documentation pages are quite "human".
Let's consider what it might be like for the (perhaps junior) developer who is
writing the tutorial. In each example there's a need for a demo, so somebody
took a widely used dataset to explain how their tools work. The goal for documentation
pages is to focus on how the tool needs to be used, so I totally see how the dataset
won't get the attention it needs. Both the load_boston and the adult dataset are
very common examples on blogs and books too. So why would anybody not use them?
That's why I don't think it's productive, or even fair, to start pointing fingers and passing a ton of blame to any particular individual. There is an unwritten norm in the community to use popular datasets in a demo because that way you don't need to explain the dataset. Can you really blame anybody to not second-guess the norm? Keeping that in mind, the issue here is more like ignorance than malice. Very much like a "don't hate the player, hate the game"-kind of a situation.
The world does need to move forward though, so how might we change the game?
I guess the main thing to do is to just keep opening GitHub issues.
So if you ever see a variant of load_boston that isn't acknowledging the issues
with the dataset, maybe just open a ticket. If you're strict, but not hostile,
odds are folks will listen. So far all maintainers responded professionally and
changed their docs when they were made aware of the issue.
I'm hoping folks would join me in this so that hopefully we can change the norm for machine learning demos. If we're going to be demonstrating the merits of machine learning, we really need to stop using gender or skin color to predict a house price or a salary.
Keeping Track
I'll be keeping track of requested changes below here.