Bad Labels

I write a lot of blogposts on why you need more than grid-search to properly judge a machine learning model. In this blogpost I want to demonstrate yet another reason; labels often seem to be wrong.
What I'll describe here is also available as a course on [calmcode.io](https://calmcode.io/bad-labels/introduction.html).Bit of Background
It turns out that bad labels are a huge problem in many popular benchmark datasets. To get an impression of the scale of the issue, just go to labelerrors.com. It's an impressive project that shows problems with many popular datasets; CIFAR, MNIST, Amazon Reviews, IMDB, Quickdraw and Newsgroups just to name a few. It's part of a research paper that tries to quantify how big of a problem these bad labels are.
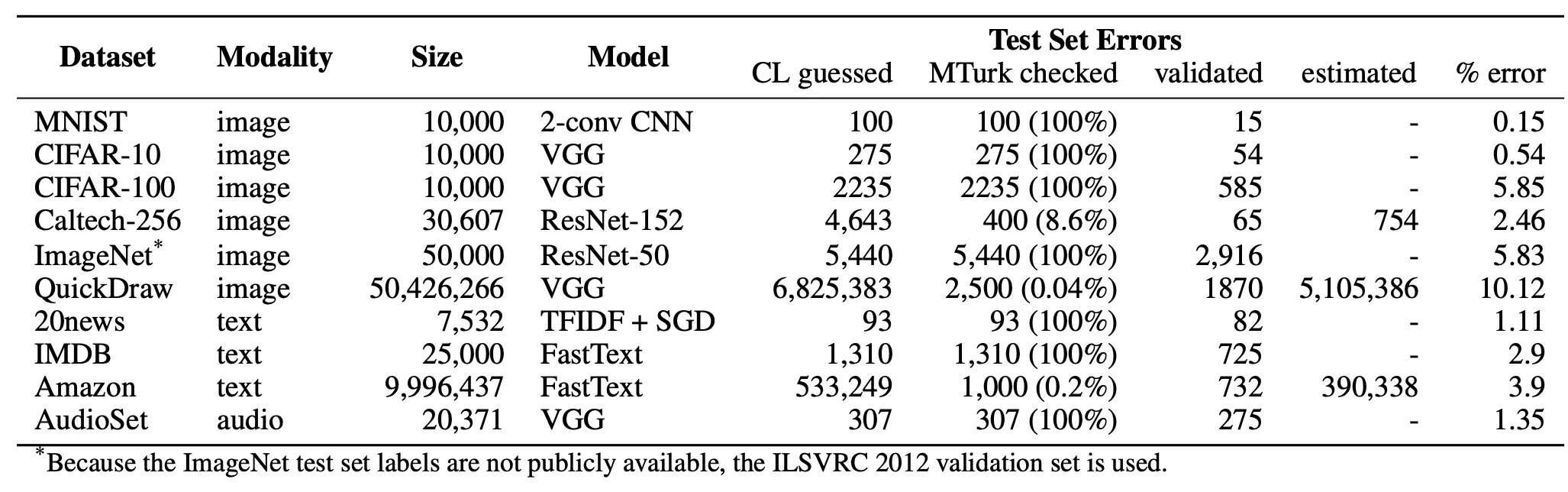
The issue here isn't just that we might have bad labels in our training set, the issue is that it appears in the validation set. If a machine learning model can become state of the art by squeezing another 0.5% out of a validation set one has to wonder. Are we really making a better model? Or are we creating a model that is better able to overfit on the bad labels?
Another Dataset
The results from the paper didn't surprise me much, but it did get me wondering how easy it might be for me to find bad labels in a dataset myself. After a bit of searching I discovered the Google Emotions dataset. This dataset contains text from Reddit (so expect profanity) with emotion tags attached. There are 28 different tags and a single text can belong to more than one emotion
The dataset also has an paper about it which explains how the dataset came to be. It explains what steps have been taken to make the dataset robust.
- There are 82 raters involved n labelling this dataset. Each example should have been at least 3 people checking it. The paper mentions that all the folks who rated were from India but spoke English natively.
- An effort was made to remove subreddits that were not safe for work or that contained too much vulgar tokens (according to a predefined word-list).
- An effort was made to balance different subreddits such that larger subreddits wouldn't bias the dataset.
- An effort was made to remove subreddits that didn't offer a variety of emotions.
- An effort was made to mask names of people as well as references to religions.
- An effort was made to, in hindsight, confirm that there is sufficient interrated correlation.
All of this amounts to quite a lot of effort indeed. So how hard would it be to find bad examples here?
Quick Trick
Here's a quick trick seems worthwhile. Let's say that we train a model that is very general. That means high bias, low variance. You may have a lower capacity model this way, but it will be less prone to overfit on details.
After training such a model, it'd be interesting to see where the model disagrees
with the training data. These would be valid candidates to check, but it might
result in list that's a bit too long for comfort. So to save time you can can
sort the data based on the predict_proba()-value. When the model gets it wrong,
that's interesting, but when it also associates a very low confidence to the
correct class, that's an example worth double checking.
So I figured I would try this trick on the Google emotions dataset to see what would happen. I tried predicting a few tags chosen at random and tried using this sorting trick to to see how easy it was to find bad labels. For each tag, I would apply my sorting to see if I could find bad labels in the top 20 results.
Here's some of the results:
??? note "Label = 'love'" - Weird game lol - Looks like it. I didn't make it, I just found it. - Wow, you people...
??? note "Label = 'not love'" - Very nice!! I love your art! What journal is this? I love the texture on the pages. - love love love this. so happy for the both of you. - I LOVE IT, I would love if they will make season 2... I really enjoyed it - I love this, my wife told me about something she read on reddit yesterday and I was like.... well just like ol [NAME] here!!!
??? note "Label = 'curiosity'" - I actually enjoy doing this on my own. Am I weird? - She probably has a kid by now. - So much time saved. Not. - Didn't you just post this and people told you it was dumb and not meant for this sub?
??? note "Label = 'not curiosity'" - I cant wait. I'm curious if it will give us any more insight into the incident other than what we already know. - Why do you guys hate [NAME]? I’m neutral leaning slightly positive on him. Just curious why the strong negative opinion? - What does that even mean? How does one decide right or wrong with something so vague? - Wait, this is actually a really interesting point. That could/should play a factor if he‘s a legitimate candidate. - Is it weed? I’m curious to ask if you know what weed smells like?
??? note "Label = 'not excitement'" - I am inexplicably excited by [NAME]. I get so excited by how he curls passes - Omg this is so amazing ! Keep up the awesome work and have a fantastic New Year ! - I just read your list and now I can't wait, either!! Hurry up with the happy, relieved and peaceful onward and upward!! Congratulations😎 - I absolutely love that idea. I went on an anniversary trip with a couple once and it was amazing! We had so much fun. - Happy New Year! Looks like you had a great time there! Cheers! Here’s to a great 2019 hopefully in both baseball and life!
??? note "Label = 'not joy'" - Happy cake day! Have a great day and year, cheers. - It's wonderful and gives me happy happy feels - Happy to hear this exciting news. Congratulations on your fun-filled morning. - It's good, good, good, good - good good good! - My son and I both enjoy taking pictures. It gives us pleasure. Part of the fun for us on vacation is taking pictures of new things.
??? note "Label = 'not gratitude'" - Thanks. Nice input as always. - Thanks. I didn't quite get it from the original. Appreciate the time. - This made my hump day. Thank you good sir - Excellent work thank you for this. This is why I love Reddit. - You’re amazing thank you so much!! :)
I don't know about you, but many of these examples seem wrong.
Friggin' Strange
Before pointing a finger, it'd be good to admit that interpreting emotion isn't a straightforward task. At all. There's context and all sorts of cultural interpretation to consider. It's a tricky task to define well.
The paper also added a disclaimer to the paper to make people aware of potential flaws in the dataset. Here's a part of it:
We are aware that the dataset contains biases and is not representative of global diversity. We are aware that the dataset contains potentially problematic content. Potential biases in the data include: Inherent biases in Reddit and user base biases, the offensive/vulgar word lists used for data filtering, inherent or unconscious bias in assessment of offensive identity labels, annotators were all native English speakers from India. All these likely affect labeling, precision, and recall for a trained model.
Adding this disclaimer is fair. That said. It really feels just a bit too weird that it was that easy for me to find examples that really seem so clearly wrongly labeled. I didn't run through the whole dataset, so I don't have a number on the amount of bad labels but I'm certainly worried now. Given the kind of label errors, I can certainly imagine that my grid-search results are skewed.
What does this mean?
The abstract of the paper certainly paints a clear picture of what this exercise means for state-of-the-art models:
We find that lower capacity models may be practically more useful than higher capacity models in real-world datasets with high proportions of erroneously labeled data. For example, on ImageNet with corrected labels: ResNet-18 outperforms ResNet-50 if the prevalence of originally mislabeled test examples increases by just 6%. On CIFAR-10 with corrected labels: VGG-11 outperforms VGG-19 if the prevalence of originally mislabeled test examples increases by 5%. Traditionally, ML practitioners choose which model to deploy based on test accuracy -- our findings advise caution here, proposing that judging models over correctly labeled test sets may be more useful, especially for noisy real-world datasets.
So what now?
More people should do check their labels more frequently. Anybody is free to try out any trick that they like, but if you're looking for a simple place to start, check out the cleanlab project. It's made by the same authors of the labelerrors-paper and is meant to help you find bad labels. I've used it a bunch of times and I can confirm that it's able to return relevant examples to double-check.
Here's the standard snippet that you'd need:
from cleanlab.pruning import get_noise_indices
# Find label indices
ordered_label_errors = get_noise_indices(
s=numpy_array_of_noisy_labels,
psx=numpy_array_of_predicted_probabilities,
sorted_index_method='normalized_margin', # Orders label errors
)
# Use indices to subset dataframe
examples_df.iloc[ordered_label_errors]
It's not a lot of effort and it feels like such an obvious thing to check going forward. The disclaimer on the Google Emotions paper checks a lot of boxes, but imagine that in the future they'd add "we checked out labels with cleanlab before releasing it". For a dataset that's meant to become a public benchmark, it'd sure be a step worth adding.
For everyone; maybe we should spend a less time tuning parameters and instead spend it trying to get a more meaningful dataset. If working at Rasa is teaching me anything, it's that this would be time well spent.