Large Disagreement Modelling
In this blogpost I’d like to talk about large language models. There's a bunch of hype, sure, but there's also an opportunity to revisit one of my favourite machine learning techniques: disagreement.
The setup
Let’s say that you’re interested in running a NLP model. You have text as input and you’d like to emit some structured information from it. Things like named entities, categories, spans ... that sort of thing. Then you could try to leverage a large language model, armed with a prompt, to fetch this information. It might work, but there’s a fair amount of evidence that you might be better off training a custom model in the long run, especially if you’re in a specific domain. Not to mention the costs that might be involved with running a LLM, the latency involved or the practical constraints of working with a text-to-text system.
So instead of fully relying on a large language model, how might we use it effectively in existing pipelines?
The trick
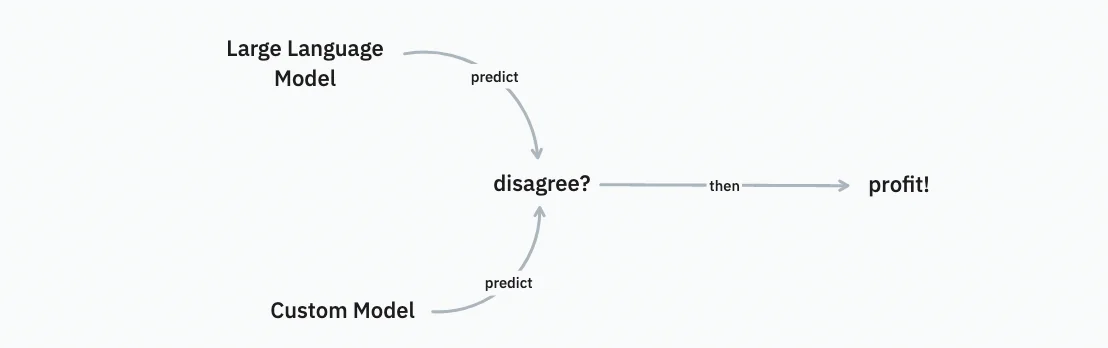
Suppose that we have an NLP pipeline locally. Let's also assume that we have a large set of unlabelled data that we'd like to annotate to improve said pipeline. Then it would be nice to have a trick that allows us to look at the subset of data that will most likely improve the model. We could try an active learning approach, were we use uncertainty estimates of the pipeline to find relevant candidates ... but with LLM's there's another trick you could use.
You could run the LLM and your own pipeline against all of the unlabelled data. You can do this on a large batch of examples with no human input required. But then, after the fact, we can look at the examples where the two models disagree and prioritise these for annotation. The "cool trick" here is that, given a good prompt, we're likely to see some examples where our original pipeline made a mistake. And it's these examples that can now get prioritised for annotation early on in the annotation process.
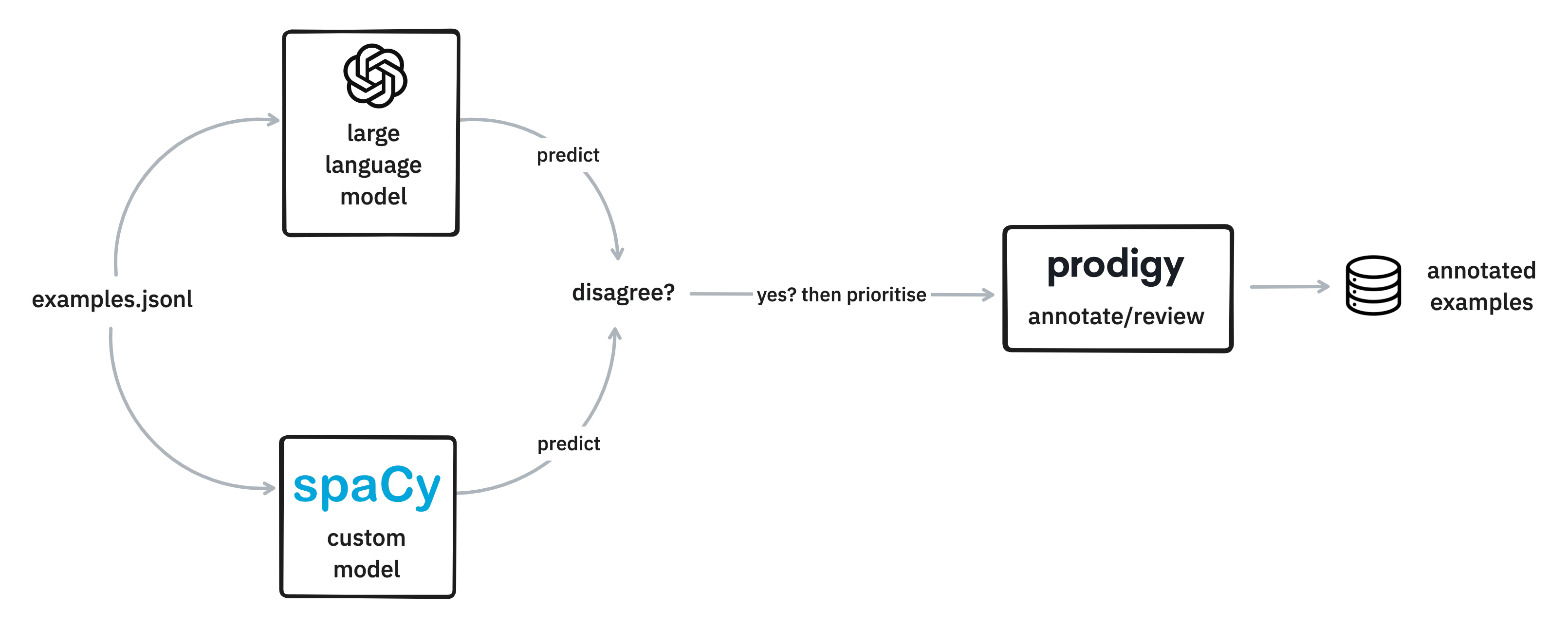
The hypothesis is that the examples where both models agree are “less interesting”. These examples might confirm the models belief, but the examples where disagreement occurs might be more impactful with regards to actually making an update.
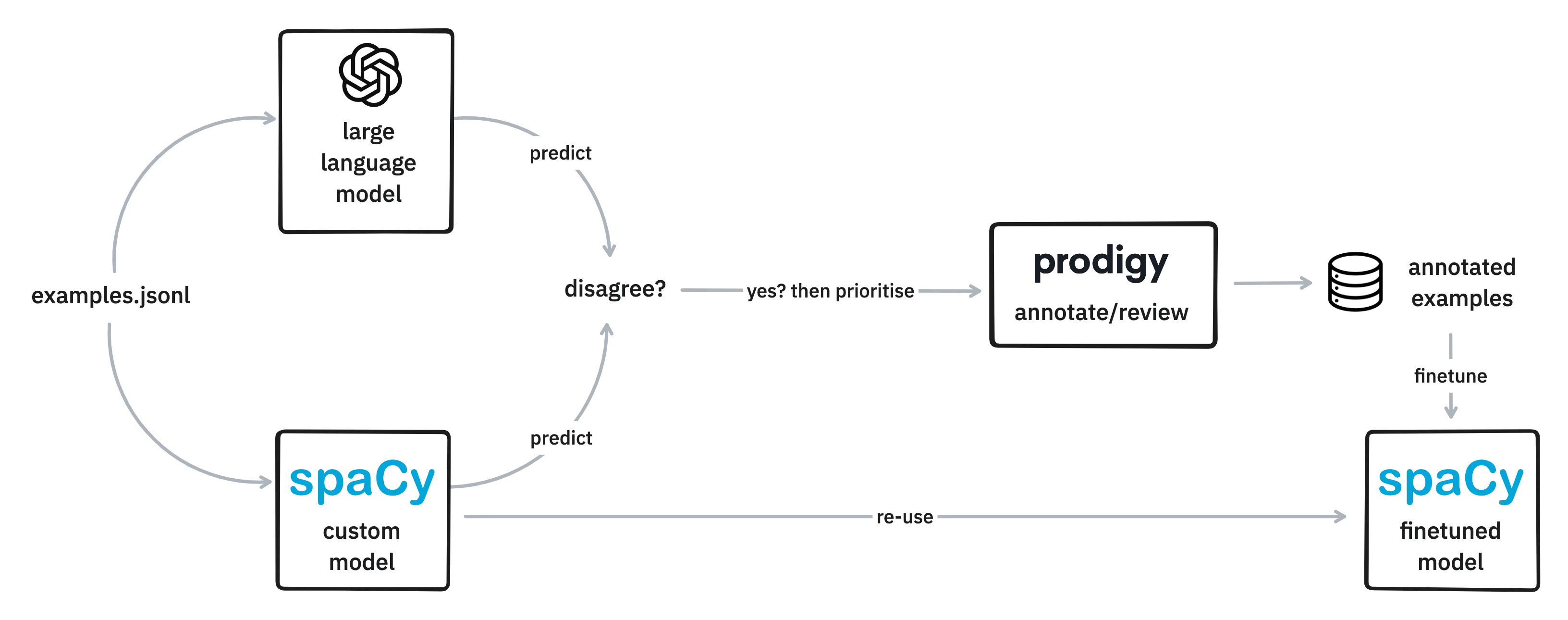
It’s like active learning, but based on the difference between two models instead of the confidence of a single one. It's a trick that I can see work especially well in early parts of an annotation project. The local model will benefit from the extra annotations, but if you see the LLM make the same kind of mistake over and over ... it might also inspire an improvement to your prompt.
??? quote "There's also another benefit."
Another big benefit of this approach is that the human remains in the loop. Large language models are amazing feats of technology but they’re certainly at risk of generating harmful text. By keeping a human in the loop, you also reduce the risk of these risks seeping into your own custom model.
Brief demo
To demonstrate this trick, I figured I’d display a demo. For this demo I’ll be leveraging data from the Guardian's content API. This gives me access to a stream of news texts from which, for demo purposes, I’ll try to extract organisations and person entities.
I wrote some code to help me do this in Prodigy. And thanks to the recent release of spacy-llm, it’s been an easy to ingerate this with LLMs. What follows is a setup for OpenAI.
First, you’ll want to define a config.cfg config file that sets up a spaCy pipeline for NER using OpenAI as the large language model. I'm going with OpenAI in this example, but you can also configure one of the alternative LLM providers.
[nlp]
lang = "en"
pipeline = ["ner"]
[components]
[components.ner]
factory = "llm"
[components.ner.task]
@llm_tasks = "spacy.NER.v1"
labels = ORGANISATION
[components.ner.backend]
@llm_backends = "spacy.REST.v1"
api = "OpenAI"
config = {"model": "text-davinci-003", "temperature": 0.3}
Next, you can load this configuration and immediately save the spaCy model to disk.
dotenv run -- spacy assemble config.cfg en_my_llm
This command ensures that we have a en_openai_llm pipeline stored on disk that we can load
just like any other spaCy model.
??? quote "Why are you using dotenv run --?"
Prefixing the `spacy` command with `dotenv run --` makes sure that the environment variables in my
`.env` file are loaded before the script that follows runs. I find it a convenient way to source
environment variables just for a single script.
Next, I've made a script that makes predictions with an en_core_web_md model as well as this new en_openai_llm model.
The script is set up so that the entity names map to the same value. The spaCy pipeline refers to an organisation via the "org" label name while the LLM model uses "organisation". This was a bit of custom code to write, but not a huge hurdle.
python cli.py predict en_core_web_md examples.jsonl out-spacy.jsonl --ner 'ORG:ORGANISATION,ORGANISATION,PERSON,DATE' --annot-name spacy-md
python cli.py predict en_openai_llm examples.jsonl out-llm.jsonl --ner 'ORG:ORGANISATION,ORGANISATION,PERSON,DATE' --annot-name llm
??? quote "Contents of cli.py."
```python
import time
from pathlib import Path
import tqdm
import srsly
import spacy
from radicli import Radicli, Arg
from dotenv import load_dotenv
from prodigy.util import set_hashes
from prodigy import get_stream
from prodigy.components.preprocess import add_tokens
cli = Radicli()
load_dotenv()
def predict_nlp(stream, nlp, ner_mapping, n=1000):
tuple_stream = ((ex['text'], ex) for ex in stream)
doc_tuples = nlp.pipe(tuple_stream, as_tuples=True)
for i, (doc, ex) in tqdm.tqdm(enumerate(doc_tuples), total=n):
if i >= n:
break
d = doc.to_json()
entities = []
for e in d['ents']:
if e['label'] in ner_mapping.keys():
e['label'] = ner_mapping[e['label']]
entities.append({
"label": e['label'],
"start": e['start'],
"end": e['end'],
})
ex['spans'] = entities
yield ex
def generate_mapping(mapping_str: str):
mapping = {}
for kv in mapping_str.split(","):
try:
k, v = kv.split(":")
mapping[k] = v
except ValueError as e:
mapping[kv] = kv
return mapping
def add_info(stream, name=None):
for ex in stream:
if name:
ex['_session_id'] = name
ex['_annotator_id'] = name
ex['timestamp'] = int(time.time())
yield ex
@cli.command(
"predict",
model=Arg(help="spaCy model"),
input_path=Arg(help="input path"),
output_path=Arg(help="output path"),
ner=Arg("--ner", help="NER mapping"),
annot_name=Arg("--annot-name", help="name of the annotator")
)
def predict(model: str, input_path: Path, output_path: Path, ner: str=None, annot_name: str= None):
"""Save spaCy model predictions."""
nlp = spacy.load(model)
stream = get_stream(input_path)
ner_mapping = generate_mapping(ner)
stream = predict_nlp(stream, nlp, ner_mapping=ner_mapping, n=1000)
stream = add_tokens(nlp, stream, overwrite=True)
stream = add_info(stream, name=annot_name)
srsly.write_jsonl(output_path, stream)
```
Finally, you can upload these two files to Prodigy and start the review recipe to see when the models disagree.
# Load the data into Prodigy
python -m prodigy db-in guardian out-spacy.jsonl
python -m prodigy db-in guardian out-llm.jsonl
# Start the review recipe
python -m prodigy review reviewed guardian --view-id ner_manual --label ORGANISATION,PERSON,DATE
Here are some examples of the two models disagreeing.
Example 1
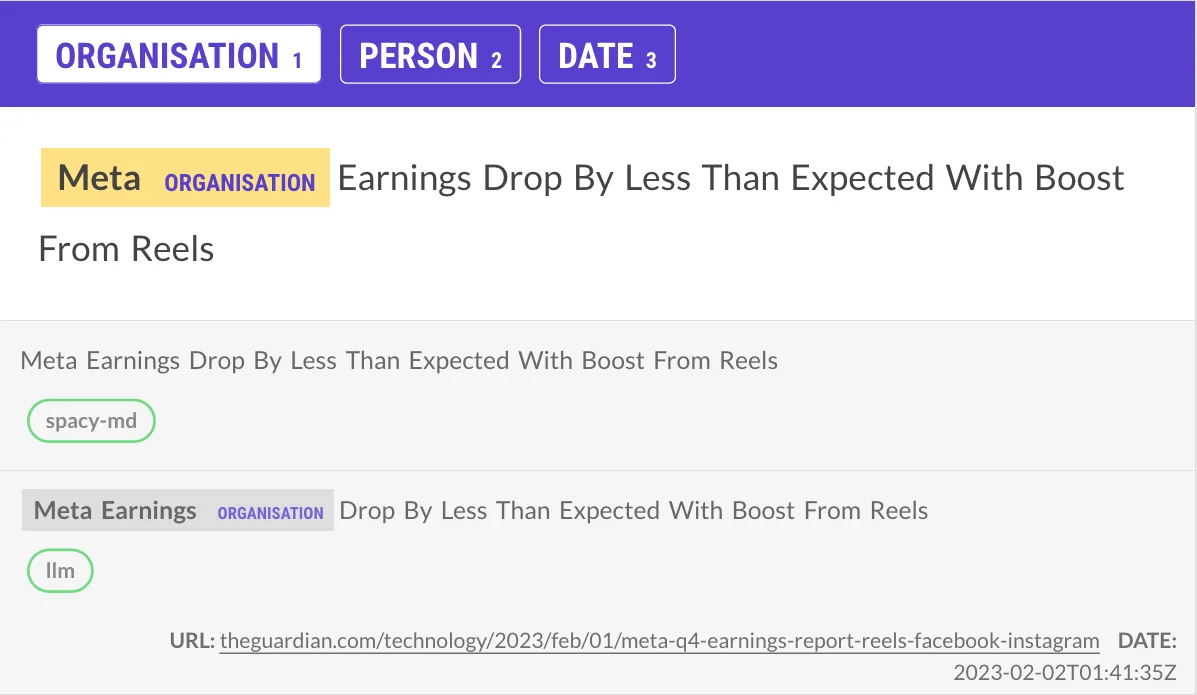
This example is interesting because both models are wrong. It's also an example where each word is capitalised, which is likely confusing the models. I can also imagine that the spaCy model was trained on a corpus that's unaware of "Meta" as a company, which isn't helping.
Example 2
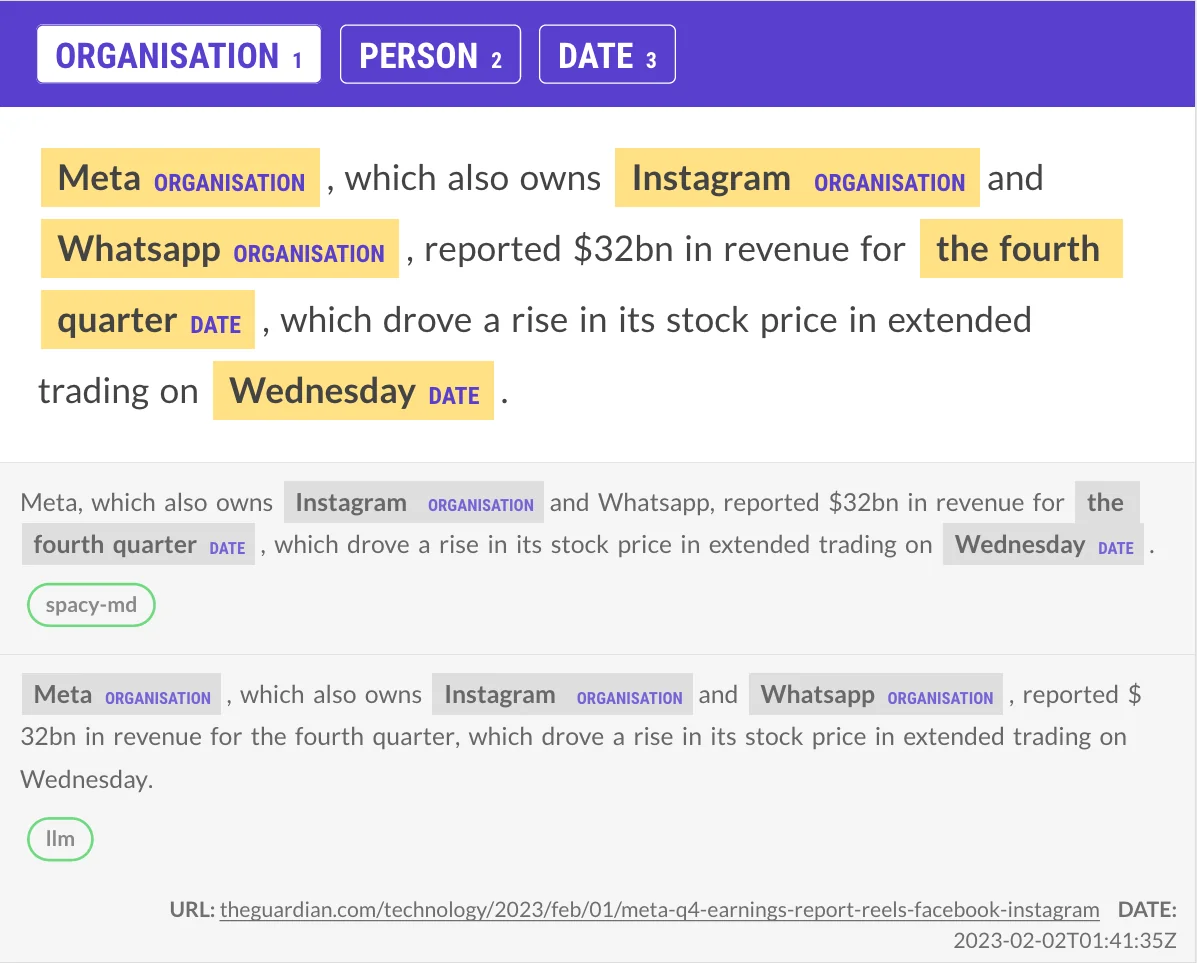
Again we see that the spaCy model has issues with some of the company names, but notice how the LLM is having trouble with the dates? These examples use zero-shot learning with a very basic prommpt that just mentions the label name. So using few-shots, or giving a more elaborate explanation of the label would likely help here.
Example 3
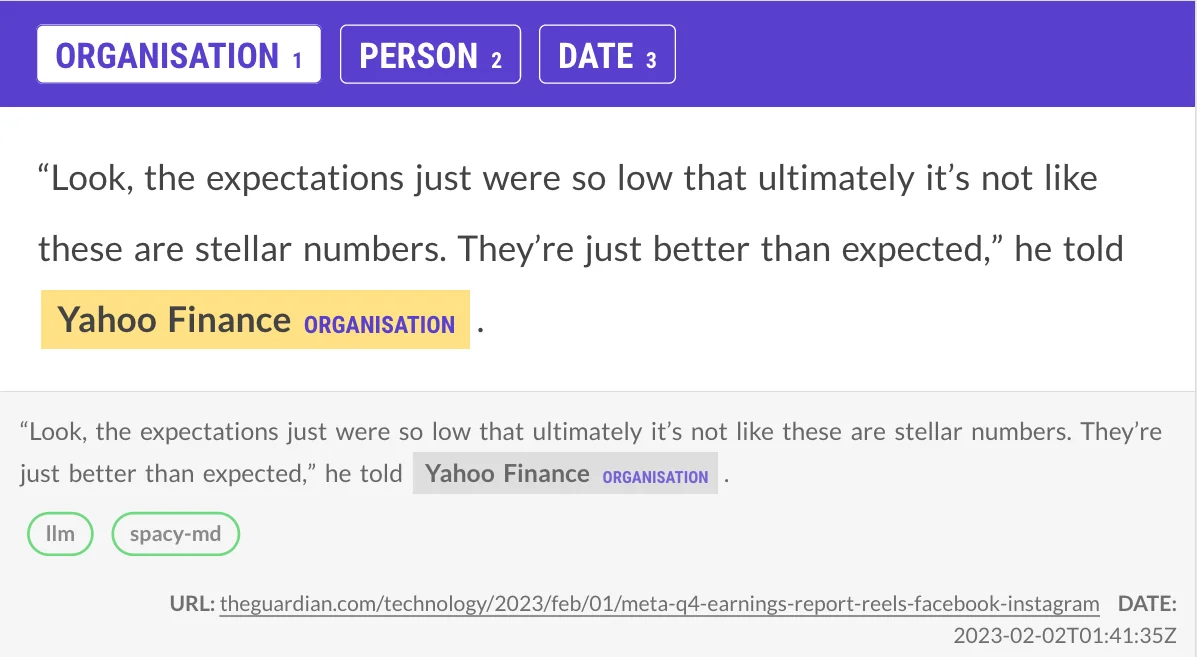
This is an example where both models agreed, which also happens. Examples like this are easy to skip, or possibly even auto-accept.
The Gist
I've found that going through these examples like this really helps me appreciate the difference between the LLM approach and the pretrained model. Every time when I look at the disagreement between them I'm usually inspired to write a better prompt for the LLM while I also gather more training data that improves the local pipeline.
It just really seems like a nice evolution of the "disagreement between models"-trick that I've already enjoyed using for so long. It really remains just a "trick", not an everything-solving-mega technique, but having a new trick that's easily moldable to a lot of situations is still very nice.
??? quote "Other tricks?"
And there's a bunch of other tricks that I like to use while labelling too.
- there's ["normal" active learning](https://modal-python.readthedocs.io/en/latest/)
- [bulk labelling](https://www.youtube.com/watch?v=gDk7_f3ovIk&list=PLBmcuObd5An56EbwRCtNWW9JnUckO7Xp-&index=12)
- [single label UMAP tricks](https://www.youtube.com/watch?v=s0Y45xscE-0&list=PLBmcuObd5An56EbwRCtNWW9JnUckO7Xp-&index=9)
- [finetuning techniques for embeddings](https://www.youtube.com/watch?v=DmH3JmX3w2I&list=RDCMUCFduT4kW_eLDbEW6XoA5F0A&index=6)
- [doubtful label detection](https://github.com/koaning/doubtlab)
- using [ANN techniques](https://github.com/koaning/simsity) to find similar candidates of examples we got wrong earlier
- [submodular optimisation](https://github.com/jmschrei/apricot/) to cover the example space
But I guess one of my OG favorites is just to do this:
- Not worry too much about tricks at less and just sit down label for an hour.
- Reflect.
New ways to iterate on data and models
These LLM techniques to help annotate excite me. They offer new ways to kickstart NLP projects while still getting the best of both worlds. The large language models offer a lot of flexibility and are easy to configure, but are typically very heavy. But with disagreement techniques they can become an aid to quickly create training data for a much more lightweight (and therefore more deployable) model for a specific use-case.
While this blogpost highlights a technique for named entities, it’s also good to know that there are other use-cases for large language models too! You can find the new OpenAI features for Prodigy here, which also lists recipes for text classification. There’s also a very interesting recipe for terms which allows you to generate relevant terms that can be re-used for weak supervision modelling. There's even recipes that allow you to do prompt engineering which can help you write better prompts for your language models.
So feel free to experiment, and ping me online if there’s any feedback!
??? quote "Another reason to get excited" There’s also another reason to be excited. While it is hard to predict the future, but it’s pretty easy to see how many alternatives to OpenAI will pop up. Today there are online providers that are easy to set up, but we may also see models soon that are light enough to run on your own laptop.
??? quote "A caveat on performance"
You may have noticed that I'm using `en_core_web_md` which, on paper at least, isn't
as performant as `en_core_web_lg` or `en_core_web_trf`. You may also observe that I'm
running OpenAI in a zero shot manner, and the predictions would likely improve if I did
some few-shot tricks. I could also have chosen to add a pretrained Huggingface model to
the mix.
These are all fair observations and it makes sense to consider all of this in a real-life
scenario. But the main point I'm trying to make here is that with _very low effort_ we now have
tools at our disposal to "pull off the disagreement trick" in a short amount of time. *That* is
very new and exciting, and something that can really shave off some time when you're getting
started with a new project.
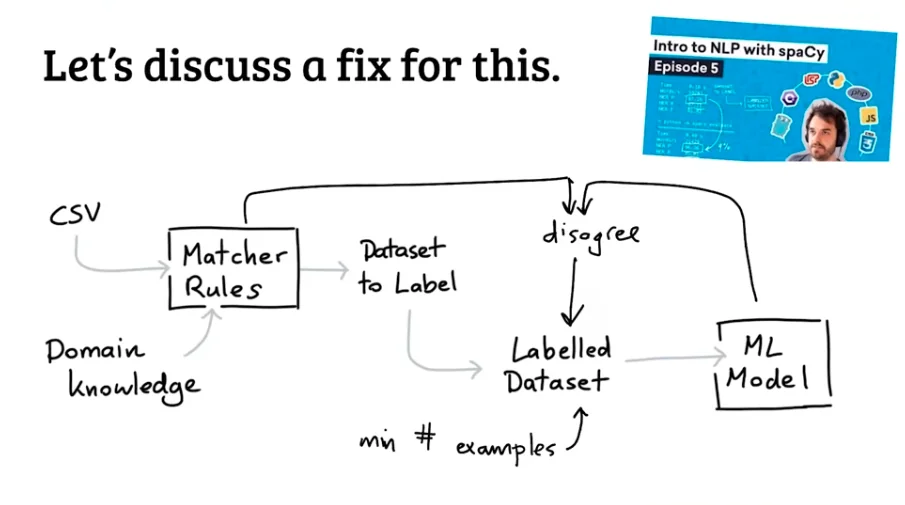
Note that you can also do something similar with spaCy and pattern files, which I've demo'ed
a few years ago at [PyData Eindhoven](https://www.youtube.com/watch?v=nJAmN6gWdK8).
!!! quote "Disclaimer" I currently work for Explosion, which is the company behind Prodigy. It's a great (!) tool. One that I've been using well before I joined the company, but folks should be aware that it's a paid tool and I now work for the company that makes it. Hence, a disclaimer.