Roman Reasoning
Romans are well known having for their numbers system but geez ... did they have it hard.
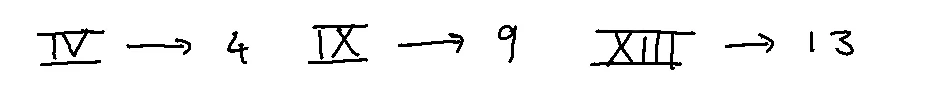
Look at the numbers for a while and you will recognize how hard these numbers are to work with. Seriously. You can't think in fractions or in rational numbers, which is a serious constraint. But worst of all, there is no definition for zero.
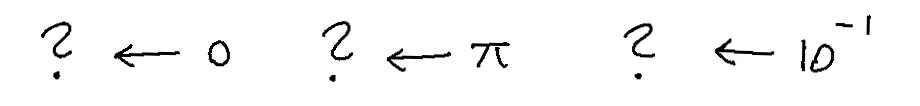
Consider the decimal system we're used to today. What is the prime feature? It's the idea of zero! The romans did not have a notation for it. Think about how limiting this is!

By introducing the notion (and notation!) of zero you suddenly get the opportunity rethink numbers a bit.
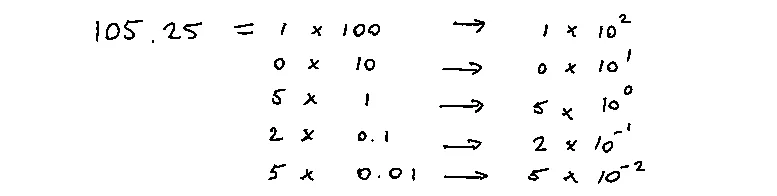
Once you have a decimal system of numbers, you realize that multiplying by ten is a common task because it is baked into the grammar of the notation. It takes a very consious mind to switch from roman numbers to numeral ones but once you're there you can unconsiously explore numbers in a more interpretable manner. I can't even imagine how a mind can conjure the idea of powers without having the decimal system to build on.
Back when I taught calculus, this bit of number theory was the first lecture. It's plainly a great lesson of mathematics; notation actually matters and you really need to be aware of that. Notation is a user interface for thoughts and a way to serialise ideas. If you get this part wrong you will risk being stuck in translation when you're trying to clearly conceptualize abstract thoughts. It will be so hard to explore and generalize problems if you cannot communicate them clearly.
The most powerful idea here is not to brag about how good our language of math is right now. Instead the idea is to keep wondering. When we are better at communicating ideas, will the ideas become better?
The answer is 'very yes'.
Recent Example
I was playing around with a heuristic problem and I wrote a small evolutionary algorithm for it. It looked something like this (it's pseudo-python code).
population = [init_chromosome() for i in range(100)]
for gen in generations:
# first we calculate the scores per individual
# and we keep the best performing members of the population
scores = [calc_score(p) for p in population]
population = sorted(population, key=scores)[:50]
# from the survivors we make new offspring
for _ in range(50):
parent1, parent2 = pick_parents(population)
child = combine(parent1, parent2)
population.append(child)
# the new population will mutate
for i, p in enumerate(population):
population[i] = mutate(p)
The code (at least, to me) is pretty clear. I've abstracted lot's of details into functions which makes the code clean. Still, it might help to add a diagram of what is happening.
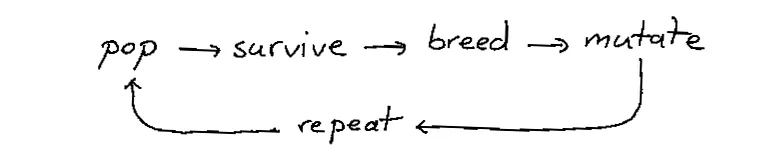
Looking at the code and looking at the diagram one cannot help but wonder; is the code really the clear communication device here? Or is the diagram better? It sort of feels like for-loops are kind of like the roman numbers. They represent a concept but they are not ideal methods of communicating. They merely facilitate the execution of ideas. I would prefer the code invites evolution of ideas instead.
So I'll attempt a rephrase of the code Let's see if we can rewrite it such that the code actually starts looking like the diagram. Here's a first attempt.
pop = Population(creator=init_chromosome, members=100,
score_func=calc_score)
for gen in generations:
pop = (pop
.survive(p=0.5)
.breed(parent_picker=pick_parents, combiner=combine)
.mutate(mutate_func=mutate))
There's a lot less boilerplate and this brings in a lot of benefits.
- There is less boilerplate so it is easier to maintain. The user can spend more time getting the
pick_parents/init_chromosomefunctions right. Less clutter means more focus on the parts of the sytem that deserve the most attention on. - We are invited to play around more. It is much easier to swap a
mutatefunction with an alternative. It's also much easier to swap the order of steps around. Wantmutatebefore youbreed? Have at it! Less worry about the details of thefor-loop means higher iteration speed. It's meta, but evolution says that this is better. - The
populationobject is a noun while the actions that are performed on it are verbs (survice,breed,mutate). Notice that a verb tells uswhatis happening while the function that goes in tells ushowthat action is being performed. It is much easier to reason about a sequence of steps when the description is close to actual human language. - There's also a nice separation of concerns when it comes to performance. Since the loops are abstracted away we get the opportunity to parallise the for loop without bothering the domain expert with this task. You can allmost call this
map-reproduce.
When you start to notice these benefits you also play around with other ways in which this method can be used. For example, we might add keyword arguments to add more expressive behavior to the evolution steps.
pop = Population(creator=init_chromosome, members=100,
score_func=calc_score)
for gen in generations:
pop = (pop
.survive(p=0.5)
.breed(parent_picker=pick_parents, combiner=combine)
.mutate(mutate_func=mutate, noise=10)
.survive(p=0.1)
.breed(parent_picker=pick_parents, combiner=combine)
.mutate(mutate_func=mutate, noise=1))
This is cool because we get to re-use parts. We can still use the mutate function but we're now able to tell the algorithm to alternate between high noise and low noise.
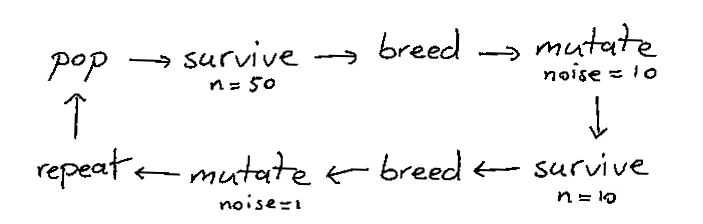
There's still a for-loop in there though. And we can remove it if we introduce yet another abstraction.
pop = Population(creator=init_chromosome, members=100,
score_func=calc_score)
evo = (Evolution()
.survive(p=0.5)
.breed(parent_picker=pick_parents, combiner=combine)
.mutate(mutate_func=mutate, noise=10)
.survive(p=0.1)
.breed(parent_picker=pick_parents, combiner=combine)
.mutate(mutate_func=mutate, noise=1))
pop.repeat(evo, n=generations)
By having a seperate object that represents a collection of steps we can more easily isolate the population and the actions that are being applied to it. Our evolutions can be declared much more expressively this way. Consider this one;
pop = Population(creator=init_chromosome, members=100,
score_func=calc_score)
evo1 = (Evolution()
.survive(p=0.5)
.breed(parent_picker=pick_parents, combiner=combine)
.mutate(mutate_func=mutate, noise=10))
evo2 = (Evolution()
.survive(p=0.1)
.breed(parent_picker=pick_parents, combiner=combine)
.mutate(mutate_func=mutate, noise=1))
evo3 = (Evolution().repeat(evo1, n=10).repeat(evo2, n=20))
pop.repeat(evo3, n=30)
Here's the associated diagram.
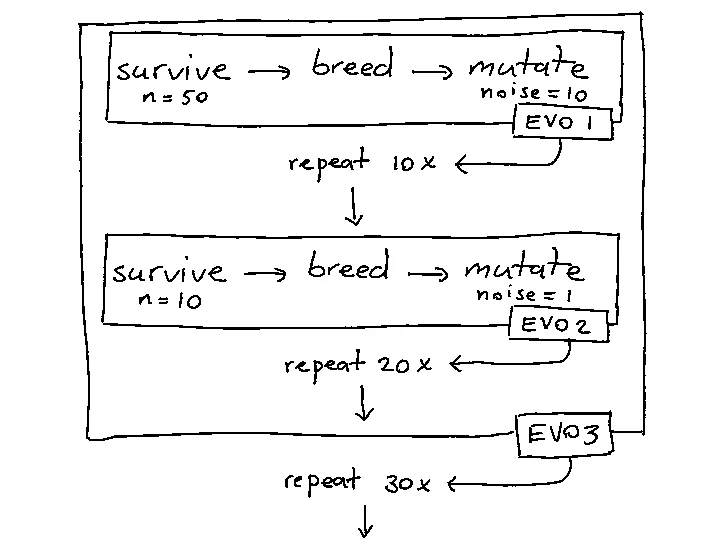
We're nearing the moment when I prefer looking at the code for clarity.
Why this matters
Here's the code that you'd need to type if you did not have a Population or a Evolution as a vantage point and had to resort to for-loops instead.
population = [init_chromosome() for i in range(100)]
# start outer repeat step
for evo3 in range(30):
# start the evolution with the small noise param
for evo1 in range(10):
# first we calculate the scores per individual
# and we keep the best performing members of the population
scores = [calc_score(p) for p in population]
survivors = sorted(population, key=scores)[:50]
# from the survivors we make new offspring
for _ in range(50):
parent1, parent2 = pick_parents(population)
child = combine(parent1, parent2)
population.append(child)
# the new population will mutate
for i, p in enumerate(population):
population[i] = mutate(p, noise=10)
# start the evolution with the medium noise param
for evo2 in range(20):
# first we calculate the scores per individual
# and we keep the best performing members of the population
scores = [calc_score(p) for p in population]
survivors = sorted(population, key=scores)[:10]
# from the survivors we make new offspring
for _ in range(90):
parent1, parent2 = pick_parents(population)
child = combine(parent1, parent2)
population.append(child)
# the new population will mutate
for i, p in enumerate(population):
population[i] = mutate(p, noise=1)
This code smells bad and the comments aren't helping. There's repeating parts so there is a risk of a copy-paste bug in there. But that's not the main issue.
The main issue is that this way of writing code will not inspire anyone to find the most appropriate algorithm. There's too much boilerplate. Too many moving parts. My mind is stuck in endless translation. It's unlikely to do any meaningful iterations from this standpoint. It's like trying to understand the square root while all I have are roman numbers as a vehicle.
Food for Reflection
Just like you'll never become a great driver when your mind is pre-occupied with understanding how the engine works you'll never become a great algorithm designer if you don't allow yourself to consider a new vantage point.
When we are better at communicating ideas, will the ideas become better?
The answer is 'very yes'. To be blunt; I've seen many codebases stuck in a 'roman' state and it has always proven to be a good idea to take the time with the team to come up with a better way of thinking. You can adapt a programming language such that it is more specific to your domain. You can even introduce the jargon of your domain in the classes and functions.
I guess that's why people sometimes make domain specific languages.
So maybe ... as a rule of thumb; when a diagram explains the steps of your system way better than your code, think about how you can get the code to look more like the diagram. More times than not, it's not impossible to get there and you will have more joy in your day-to-day as a result.
Appendix
The point I wanted to make here was that it makes sense to take a step back when you are working on a project and to wonder if you are "stuck using roman numbers". That said; it's probably not a shocker for you to learn that I've been maintaining a library (together with Rogier van der Geer) that does exactly what I've described in this post.
Feel free to play with it! It's called evol and you can just pip install it. It's an interesting project. We wrote it because the idea of exploring a grammar was very exiting. There exists a pipeline for scikit-learn but there wasn't a good pipeline for heuristics. We spent many evenings (many whiteboard markers) trying to figure out what the ideal level of abstraction was. It's not the most performant library but we like to think it is the most fun to write heuristics in.
Note that when we wrote it we didn't have an application for genetic algorithms what-so-ever. We merely imagined that this way of looking at heuristics was going to lead to better heuristics. Two years have passed by and despite our inactivity it has been downloaded 31K times.