I've been toying with embeddings again. Part of the story is that the recent LLM course inspired me to go spend some compute credits and expose myself to some new tech again. But another part of the story is that I already had been working on an experiment that needed to be picked up again.
I am happy to report there's been some serious progress on that front but I figured I might write about the sequence of experiments that led me to where I am now.
My new hobby: Arxiv data
I am interested in building a search engine that acts more like a classifier for "stuff that might interest me". There are a few topics that I know will be interesting to me. Usually it's articles that describe a new public dataset or articles about label errors in said datasets. I want to have some sort of system that can fetch these for me, as well as some other topics. These topics tend to be somewhat rare in the large pool of computer science papers so I need to do something clever to get what I want.
I grabbed all the computer science papers from a recent dump on Kaggle to start searching. This gave me about 650K abstracts. That's not huge, but it's not small either and should give me ample opportunities to experiment and play with techniques that are new to me.
As a first experiment, I figured that I might compare two things.
- First off, I was wondering if something might be gained by not just embedding the abstracts, but also embedding individual sentences. It may be easier to precisely match a single sentence as opposed to a full abstract, so that may be worth a try. A sentence has less information in it, but that might allow for a more specific match.
- Next, given that I will be playing with sentences, this felt like a great point in time to play with matryouska embeddings. These embeddings pack a neat little technique such that you can also choose to only store a subset of the embedding without loosing too much of the information. This doesn't lead to faster inferece, but it does save on a whole lot of disk space. If we're going to be storing embeddings for each sentence, then this technique may save a whole lot of disk space.
I decided to use LanceDB as my embedding backend. It felt like one of the easier options in terms of setup, mainly because everything is written to disk. It feels like SQlite in some ways, which is a really nice feeling.
Bootstrap
To get this experiment on the road, the first thing to do is to get the text into an embedded representation. I've opted to use modal for this because they make it easy to just run my embedding function on a GPU. Putting 650K embeddings into a vector retreival store is slow because of the embeddings, not because of the index.
Modal really fits this usecase nicely. The texts could be sent over the wire in batches and I would get embeddings back in my Python process. It was a pretty simple script to write, but I did choose to send the batches sequentially. That way I could make sure each batch was stored in the vector database and that I wouldn't loose anything due to a hiccup.
Here's some stats of that exercise.
| kind | embedding | embedding size | modal cost | time taken | disk space used |
|---|---|---|---|---|---|
| abstract | all-MiniLM-L6-v2 | 384 | $0.54 | 25mins | 1.7GiB |
| sentence | all-MiniLM-L6-v2 | 384 | $2.44 | 2h42mins | 7.6GiB |
| abstract | mpnet-base-nli-matryoshka | 768 | $1.60 | 1h11mins | 2.7GiB |
| sentence | mpnet-base-nli-matryoshka | 64 | $4.17 | 4h16mins | 1.9GiB |
Calculating these embeddings, even with Modal, feels like it's the most "expensive"/"slow" step in this whole setup. I can imagine that this won't just be true or my little experiment, but for most ANN search applications out there.
Checking for vibes
Most of the experiments that I've ran in the past came with a benchmark dataset of sorts. That's useful because that can give me a number of how well different approaches are. In this case I've kind of thrown those metrics out the window in favour of just checking "the vibes". So I mocked up a tiny UI with jupyter widgets that's minimal, but also just enough to let me play around and experiment.
One lesson I've learned from this experiment is that for this particular dataset you really loose a lot of context when you go for the small matryouska models with only 64 dimensions. As far as my vibes go the base all-MiniLM-L6-v2 model performed much better on sentences. This suprised my initially because the model card suggests that you don't risk loosing that much information. But the more I think about it the more I wonder if the arxiv dataset is just too different from the standard benchmarks. I also checked in with the maintaner of sentence-transformers and he was able to confirm that this is indeed the case.
On the other end of the spectrum, for embeddings that do the whole abstract, it did feel like large matryouska model gives much better vibes than the base all-MiniLM-L6-v2 model. Whenever I made the query more specific by adding more context, the large matryoshka model was able to return more and more specific results that matched my query.
??? note "A set of examples of some of the vibes"
The screenshots below are from my experimental Jupyter notebook with my custom widgets. There is a search bar on the left and a list of results on the right. The results are ordered by the cosine distance to the query.
Notice how the results change every time that I make the query more expressive. These are all queries that I've made on abstracts, not on sentences. The results show the title of each paper while the retreival is based on the abstracts.
### Pretty precise prompt

### More specific prompt

### More and more specific

Again, the results only show the titles in an attempt to fit everything on screen, but hopefully this example does a reasonable job of showing how the results change as the query becomes more specific. This is something that's incredibly hard to do with normal text based retreival and it's my impression that it helps to have embeddings with a high number of dimensions to pull this off well.
This made me realize that using the abstract embeddings with the large matryoskha model would be the simplest way to move forward. The approach with the sentences was interesting, but it felt hard to combine multiple sentences together. Sometimes my queries would be so large that the query itself contains two sentences and you could just tell that this made it much harder to search for what I wanted.
Another thing I've noticed is that it's really hard to figure out an appropriate cutoff based on the the distance metric. Sometimes documents would yield a vibe of "meh" on a cosine distance that was relatively small while other times the distance was much worse but the documents matched very nicely. Vibes are hard to quantify. It might be better if you're able to take the time and properly annotate a broad set of responses, but even then I'd be careful with how you choose to annotate your dataset. This sounds like it would be a worthy exercise in a real life scenario, but I am the parent of a young child and can only spend very little time on this. This is also why I didn't take much effort in tuning the index of the database either.
When is a query a prompt?
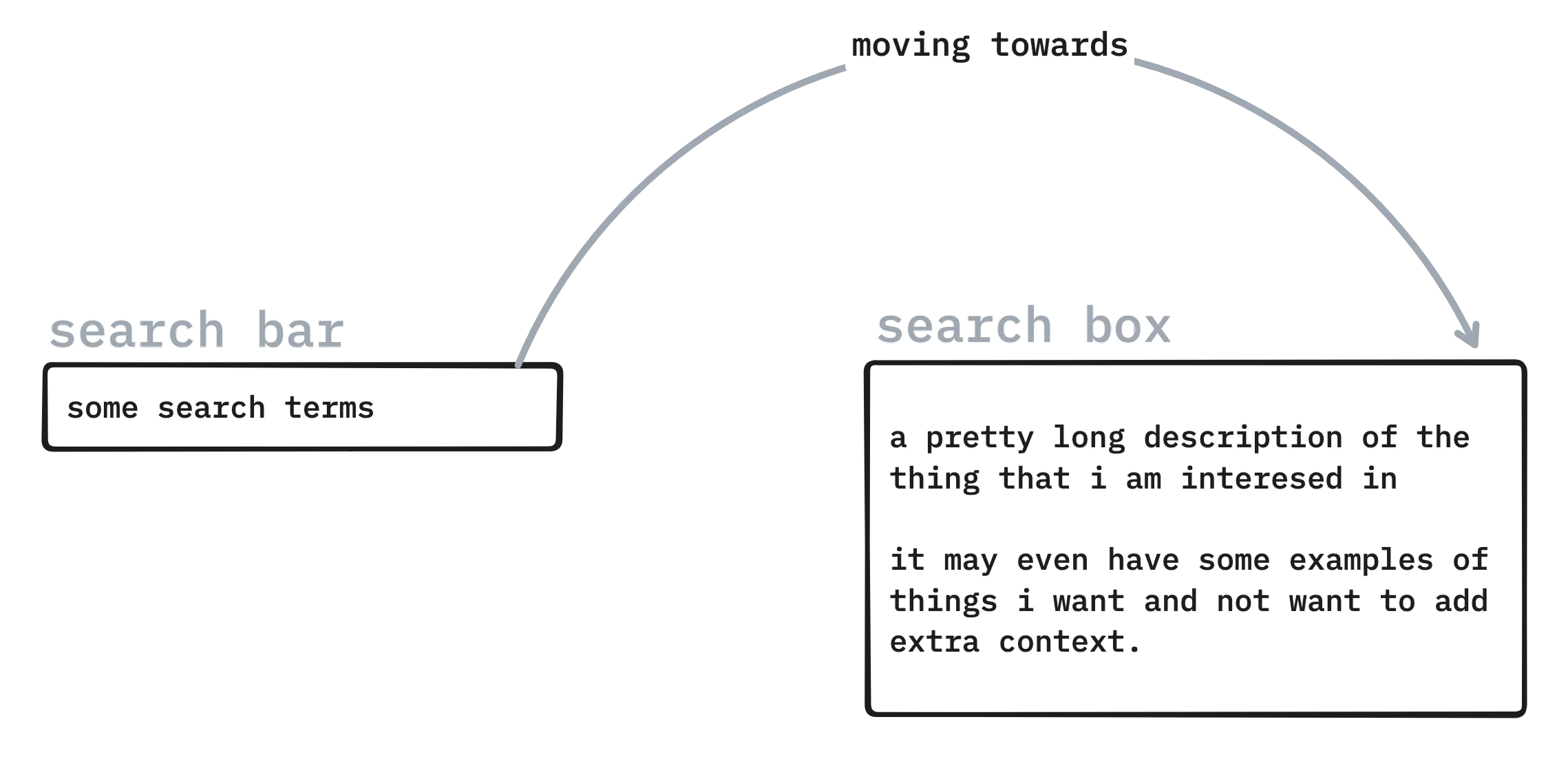
This exercise made me realise a curious thing. In this new realm of embedded search we may have an opportunity to rethink the user interface. Google may have thought me that search takes place in a "search bar". But if we're able to catch a lot of context maybe search needs to take place in a text box instead. The query will be less like a few search terms and more and more like a prompt instead, even if the prompt feels different from the one you might send to an LLM. So maybe it's time to call it a "search box" in the near future.
Promting for search is different than for a "normal LLM" though. The backend isn't generating anything, it is retreiving. So that means that you could risk a mismatch between what is queried and what is available. In terms of strategy it seems helpful to start with something that is relatively broad and known to be available. From here, proceed to mention phrases that could indicate a subcategory and drill down from there. That way, the query becomes more and more precise, but it also allows you to experiment since it's easy to backtrack. I have found that while looking for datasets about label quality that it can help to mention things like "label quality needs to be taken serious" when looking for "datasets with bad labels", just to give one example.
A final demo, and a new direction for my hobby
While exploring the retreival system with some queries that started looking more and more like prompts ... I started wondering what I could do to make the experience better. It did feel like it was hard to find the needles in the haystack.
Instead of worrying about tensors I took a step back and tried to describe what was broken. This led me to realise that sometimes it's very easy to describe what you want in words, but other times it's just a lot easier to point at something and say "not that". I was definately able to upgrade the search bar into a search box by allowing for a prompt, but it felt like an extra improvement could be made by just building a custom UI on top that allows me to add some annotations on top of the prompt.
This led to a fun tool. The easiest way to explain is to just show you, so I've made a little video that gives the full demo.
To those who can't bother with the video: what the demo boils down to is that I'm able to improve the search experience by iterating over two things at the same time.
- I am able to annotate my search results within the same session. So when a bad search result comes in, I can flag that. The good/bad flags cant then help inform the ordering of the results that come out of LanceDB. The demo uses label propogation to do this in the backend, but I can also imagine variants of this that allow for fast propogation techniques in the front-end.
- While this is happening I am also able to reset the prompt at any time and push the search in a new direction that way. I can always switch and change the prompt and the annotations that I've made. This allows me to search iteratively in a way that feels more like a conversation than a search.
I think it's the ability to be able to think of search as "something that happens interactively in a session" that really helps make it fun for me to go and find for the rare gems in the dataset. And that fun really matters! If the tool is fun to use, I will be way more likely to actually use it! Interactive search is way cooler than static search that just provides a search bar. We're not just staring at some results, you're actively able to annotate and steer the direction interactively.
There's barely any fancy methods in all of this too. It's really just some off-the-shelf ML implementations that I've used here, but the UI is what causes the whole thing to be different. I'm honestly not sure if better embeddings make the biggest impact here. Remember: negation tends to be something that's very hard to handle for many of these embedding systems. Being able to handle that by getting user feedback in a follow-up step like this is not only great for the interface, it is also great for retreival accuracy.
!!! note
This whole 'maybe this ML problem is actually more of a UI problem'-thought has been in my mind for a few years now and I'm happy to see that it's starting to pay off.
It also feels that exploring ideas like this has only started becomming possible recently with the advent of these new embedding models and the fact that there's tools like Modal/HTMX/scikit-learn that really allow me to write these kinds of experiments in an evening or two. It took me about one evening to write the script that does the embedding/vector database stuff and another evening to write the custom UI/scikit-learn code to handle sorting of the results with feedback. No team needed, just me and my keyboard.
!!! note
In the case of scikit-learn I also want to point out that without it ... it would've easily taken me another full week. People often under-estimate the power that it provides the ecosystem and scikit-learn is just beyond great in what it allows me to rapid prototype.
Future ideas
All this felt pretty interesting, but there's a few angles I want to toy with next.
- What if we're able to store the end result of a search session? We'd have annotations as well as a (collection of) prompt(s) that we can go ahead an re-use. So maybe this interface would lend itself well as a "human-in-the-loop" method of creating a bespoke text classifier? It's honestly not the worst idea when you're just getting stared with a new classificatioin use-case.
- I've never finetuned embedding models before, but it might make some sense to do that here. Arxiv text is unlike most English text out there, especially when you consider all that Latex. So maybe there is an opportunity here to get a better search by investing in a better embedding. Will need to think on how to measure "better" here though. I could also alternatively try out some embeddings that have been finetuned on academic papers.
- Part of me wonders if there's anything sensible we may be able to benchmark when we compare to binary embeddings. There are some nice binpacking techniques too for these, but not every vector backend supports these.
- Another part of me also still wonders if there's something clever we can do to leverage sentences a bit more.
- It'd be nice to be able to release this to a wider public but in order for that to scale I may want to move the label propogation to the front-end. This also needs to be fast, so maybe something-something WASM can work out swell here.
I'd also be very interested to talk to folks who are working on similar things. I consider this to be a hobby project that might have some legs and I'd be very eager to exchange notes with folks. If you'd like to do that, feel free to reach out on socials. There's a lot of tools that we can dream of in this space and I'm sure that there's a lot of low hanging fruit that I'm not aware of until I start chatting to folks about it.