The Future of Data Science is Past
After some reflection with friends and colleagues I can't help but observe an odd fact:
the Future of Data Science is Past
This isn't because data scientists try to predict the past (which granted, is pretty funny and ironic). It is also because hype and other circumstances have turned data science into a field of inflated expectations. It feels more like a certain type of dream got pushed (even sold) that didn't solve all the problems that people were hoping for.
After I started hearing that a lot of data projects fail (here's a nice example on reddit) I started thinking about what was going on. Five years ago the future was so bright that some of us may have been blinded by it. In short, the hype around algorithms forgot to mention that:
- algorithms are merely cogs in a system
- algorithms don't understand problems
- algorithms aren't creative solutions
- algorithms live in a mess
In this document I'd like to address these points one by one so that I have something to refer to. I realise that I sound a bit cynical but I'll end the blog with some hope.
Algorithms are Merely Cogs in a System
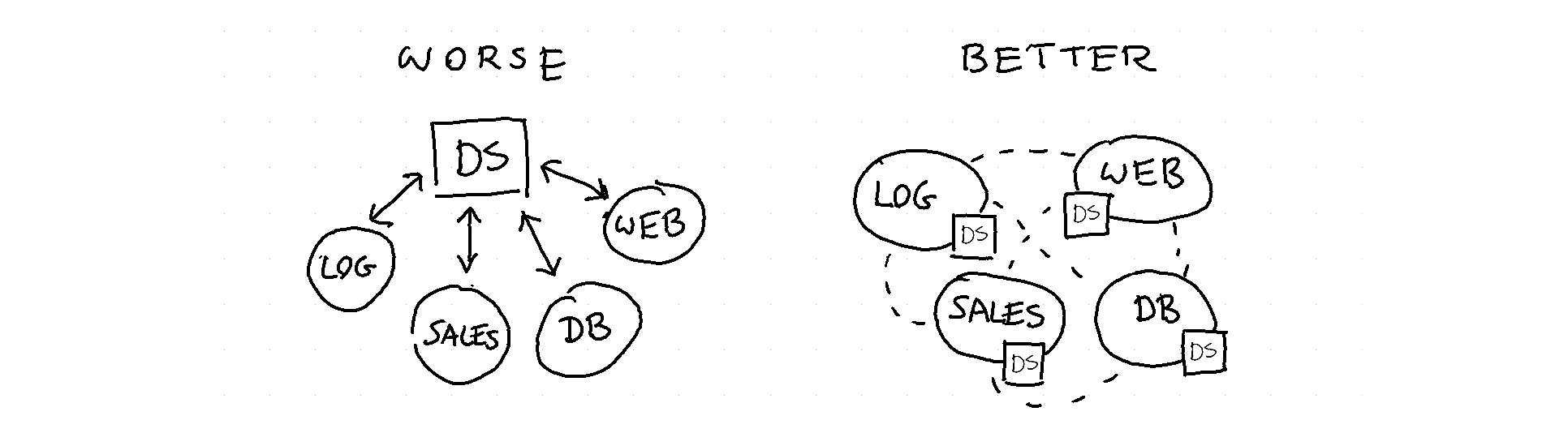
I was once put in a team to design a recommendation service for the Dutch BBC. One of the first things we did was make a drawing of what the service should look like. It looked something like this.
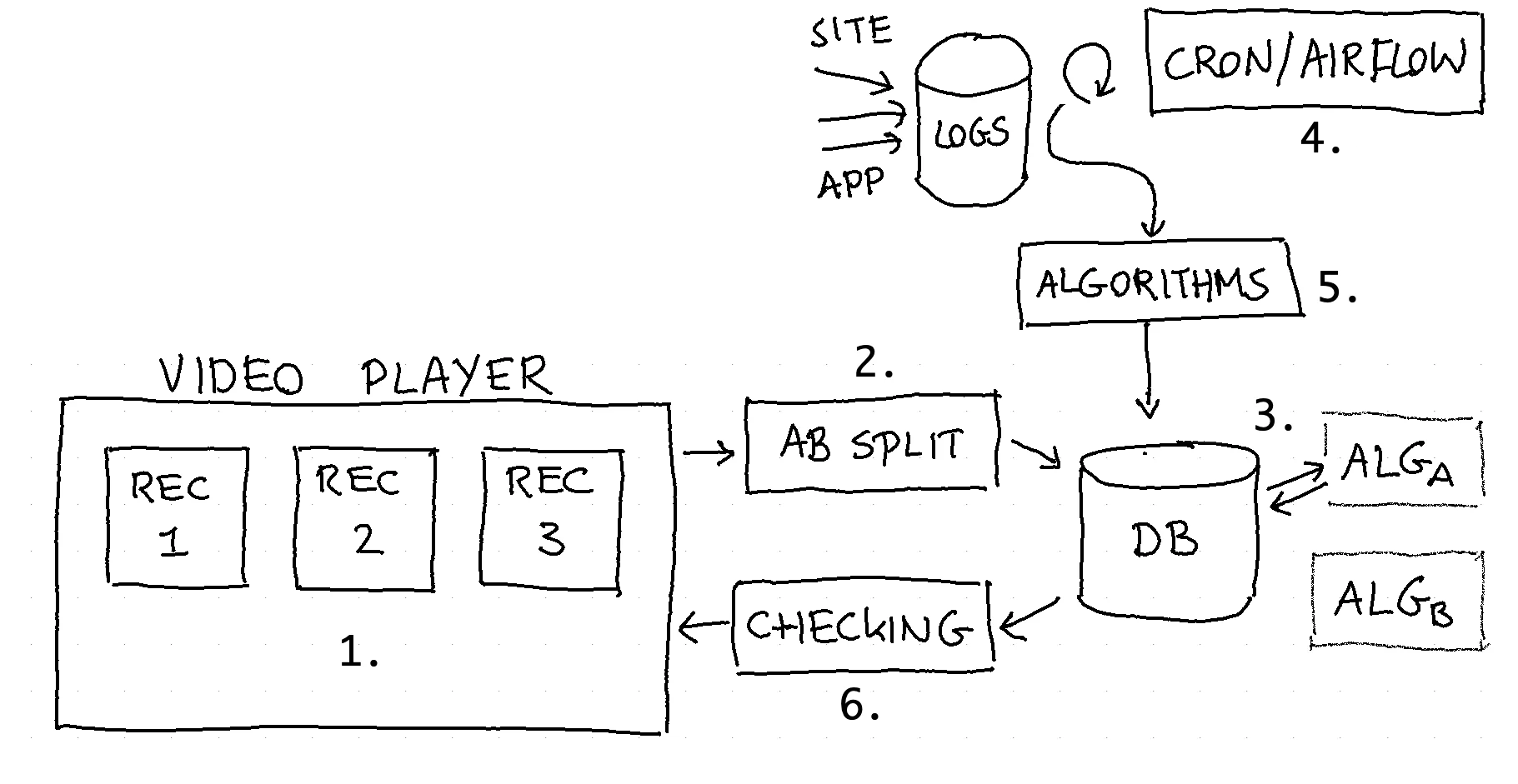
There were different parts of this design:
- The UI layer
- The AB splitting mechanism - we need this is we ever want to compare two algorithms.
- The database that caches recommendations - we need this because at scale we cannot calculate these in real time
- The scheduler that triggers a cluster to make calculations - we want to incorporate new data on a daily/hourly basis
- An algorithm that calculates new recommendations - this is the data science code that takes log files and produces recommendations
- The fallback/checker mechanism that ensures we only recommend things we're allowed to recommend.
Out of all these parts the final part (#6) is the most important in this system. It is the part that guarantees that we always have something to recommend even if any part before breaks. It is also the part that ensures that we always adhere to some very important business rules. Business rules like;
- make sure that we don't violate a license (some content may only shown during certain parts of the day)
- make sure that we don't show mature content before 22:00
- make sure we don't recommend violent shows after a kids show
It is unrealistic that a self learning algorithm is able to pick up these rules as hard constraints so it makes sense to handle this elsewhere in the system. With that in mind; notice how the algorithm is only a small cog in the entire system. The jupyter notebook that contains the recommender algorithm is not the investment that needs to be made by the team but rather it is all the stuff around the algorithm that requires practically all the work. Note that step 5 also requires communication with a big data cluster which also demonstrates that a recommender is more of an engineering investment than an algorithmic one. You don't want a pure scientist team here, you need solid engineers and developers.
This is besides the fact that a lot of good algorithms can be created with simple heuristics that don't require a maths degree. One could:
- recommend content that is often watched together
- recommend content that is often watched together unless it is too popular
- recommend the next episode
These are all fair options to at least benchmark. I would also like to point out that the latter idea is a great idea even it isn't technically machine learning. It should compete with any deep learning algorithm, any day.
Algorithms don't Understand Problems
It takes a team a lot of time to realise what problem it is actually solving. Getting this right is hard. It's even harder when the majority of the team consists of the same people. Worse; these people are trained in machine learning and prefer to keep themselves to the algorithmic part of their work.
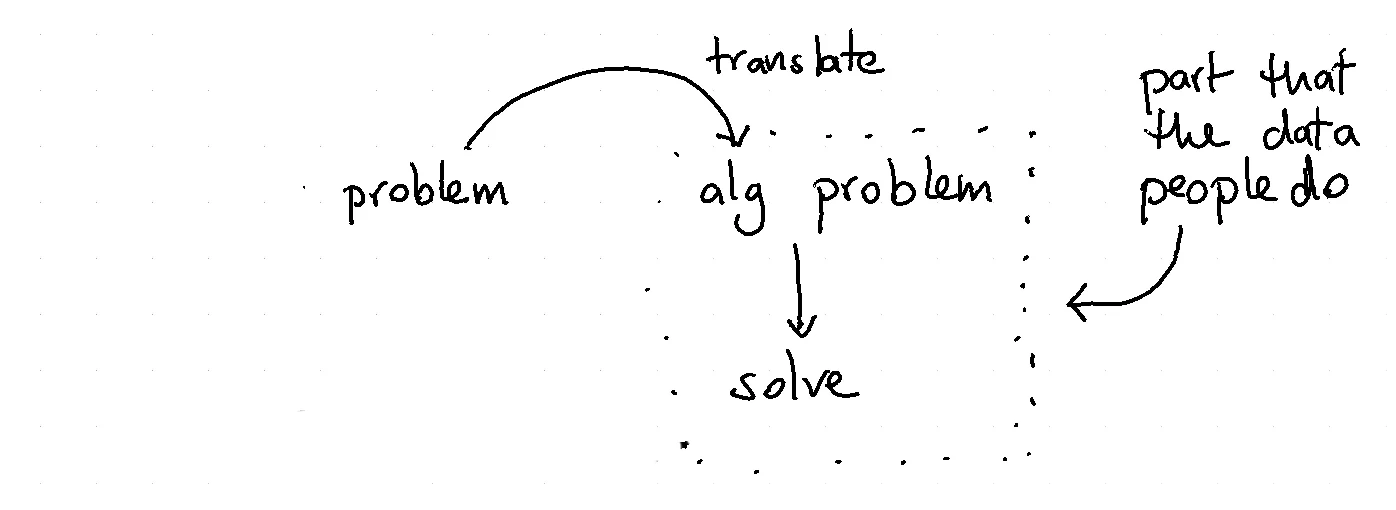
Thing can go wrong in this situation. The team might not be great at translating the actual problem into an algorithm that represents the business. At the same time, the business might not be able to adapt to a recommendation that comes out of the algorithm. Even worse, it is also possible that the algorithmic solution brings in new problems. If you're unlucky these new problems can get translated into new algorithmic problems. Before you know it you're stuck in a loop.
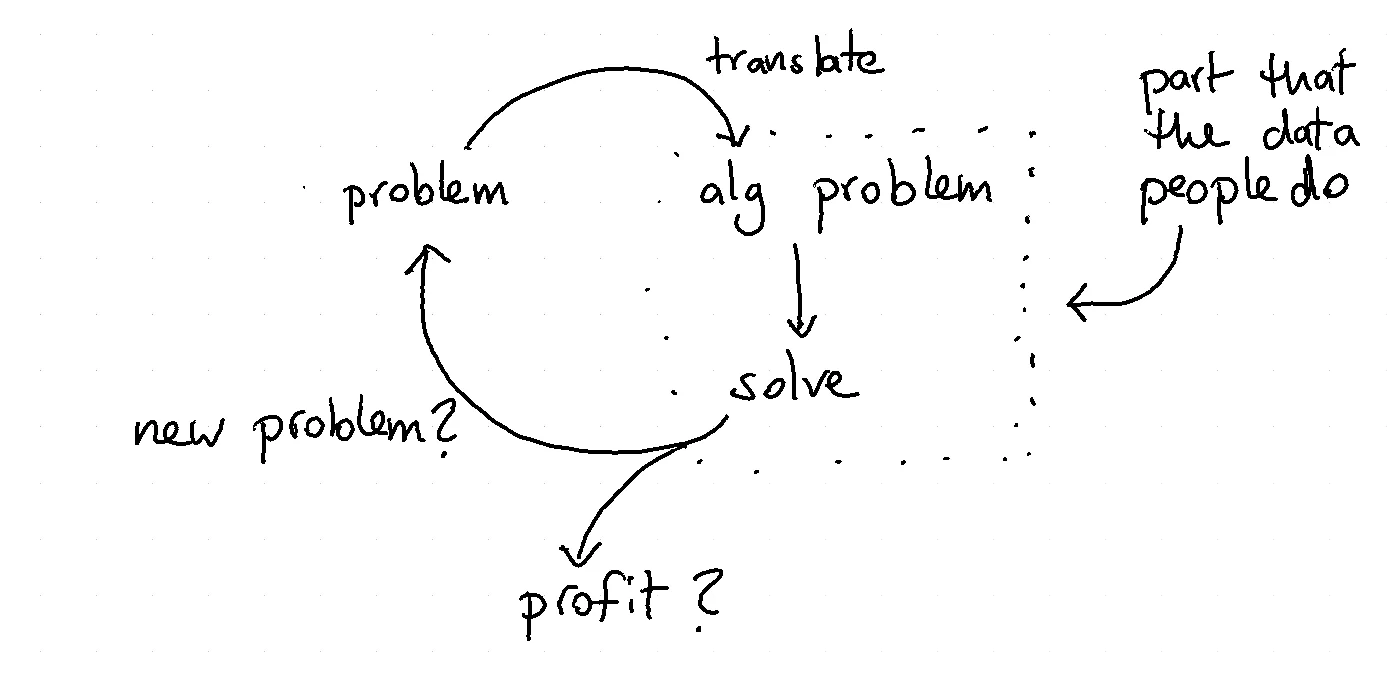
People with an algorithmic background usually tackle a problem in isolation of the system that it is in. A better approach is not to focus on the isolated part but to focus on the communication between two parts of the system. If this is not part of the problem design from the get-go then you're bound to waste resources until you realise it has to.
Let's remember the recommender usecase. It is a bad idea to expect the algorithm to magically understand that it cannot recommend mature content before 22:00. When you realise this you know that you need a checking system between the algorithm and the serving layer. It is good to realise this early in the project and not when a large chunk of the code needs to get rewritten.
One potential cure against this "isolation" way of thinking is to not have a team with data people. Instead you want to have teams that are interdisciplinary and maybe have a data person in it. A team with many backgrounds causes more discussion and a more holistic view of things that "might go wrong". It makes sense to have a UI specialist, a backend engineer, an algorithm person and a content expert in a team that is making a recommender.
It is really hard to think outside the box if your in it. By having multiple disciplines you ensure that there is always somebody who can cause a pivot. There's always somebody who thinks outside of the box that you're in.
Algorithms aren't Creative Solutions
Creative solutions to problems are usually not found by hyper-parameter search. The goal should not be to be the most efficient algorithm but the most effective. Do data teams ever consider that maybe the solution to the problem isn't a machine learning model? Why would the algorithm ever be a good starting point to solving a problem?
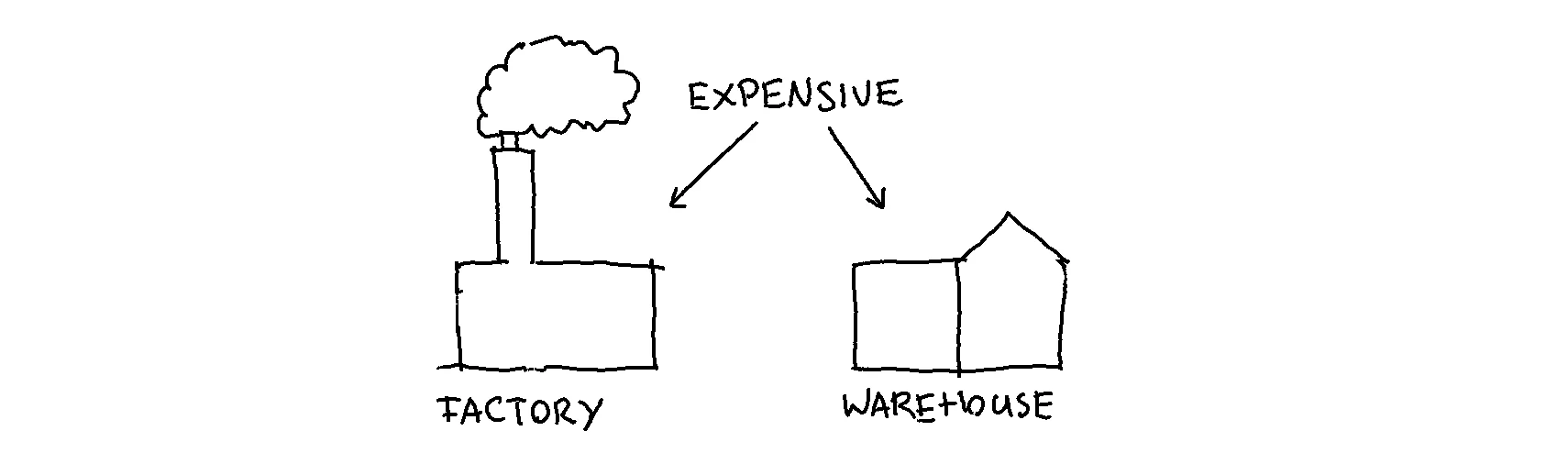
To drive this point I'm reminded of a story in the eighties about a condom brand. The business was doing well but it was having some trouble planning production. It turned out to be very hard to predict demand. Both the factory and the warehouse are expensive so people were wondering what to do about it.
Then a strategic consultancy firm came in and suggested that this was indeed a StatisticsProblem[tm]. The consultancy firm advised getting another third party involved to try to predict the demand curve. A small army of econometricians was brought in to tackle the business case.
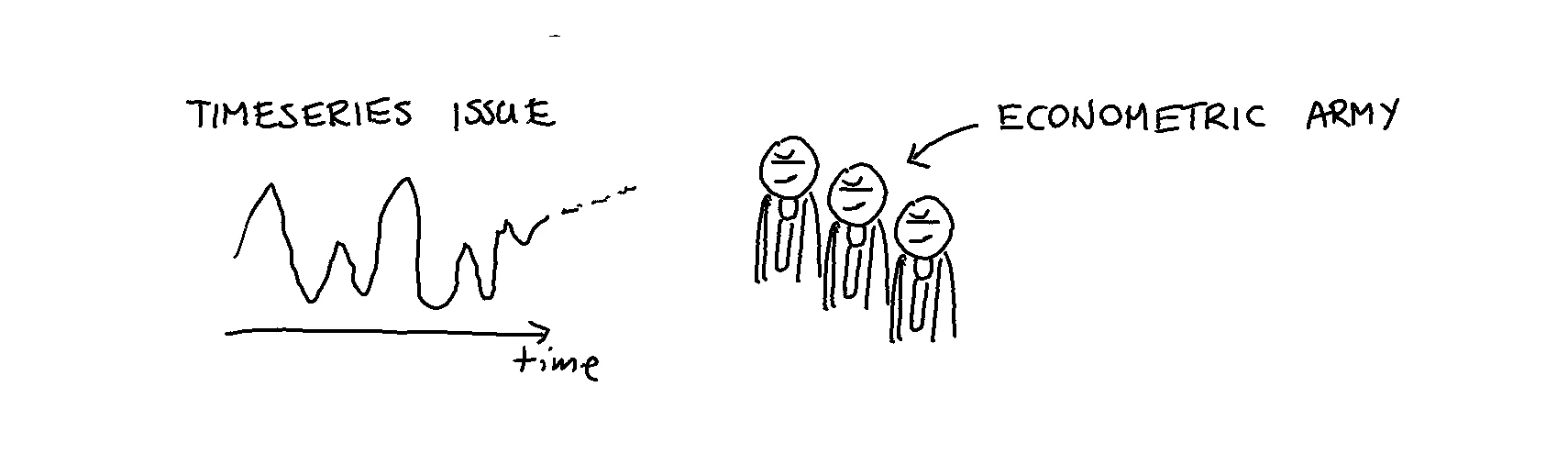
After two months (and many billed hours) the econometricians reported that no progress was made. The timeseries turned out to not show any predictable patterns that could help with the planning of either the factory or the warehouse. The original consultants and econometricians left (pockets filled) while they reminded their client of the NDA they all signed.
After a few weeks an alternative way of thinking made it's way to management and it came from a factory worker. The problem turned out to be formulated incorrectly. The factory did not need to be turned off if the company had products to produce. It merely needed to look for a product that it could produce when demand for condoms was low. If it could find a product that correlates negatively with the original product then the factory might produce all year round.
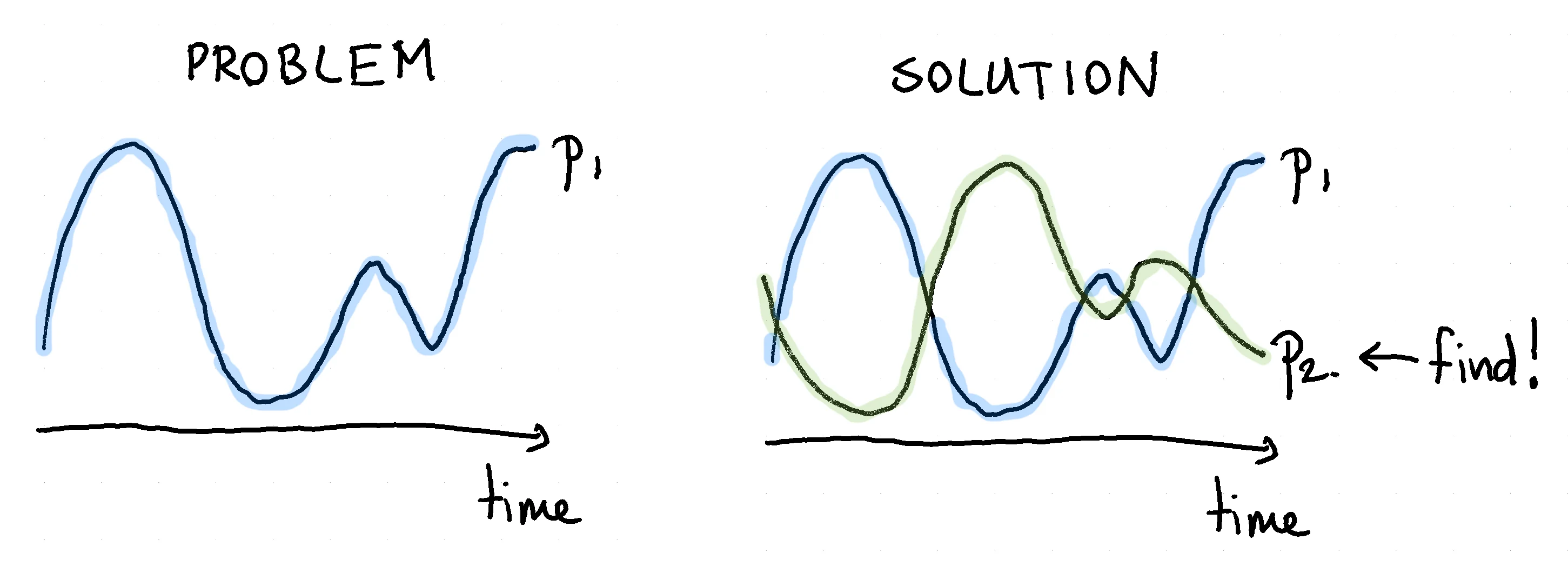
Supposedly, this is how latex pacifiers got invented.

The issue with this fable is that it is very hard to verify it's truth. Still, one might wonder what would happen if we allow ourselves to solve problems without algorithms for a change.
Algorithms Live in a Mess
From the perspective of a data scientist life is pretty easy. One gets to play in an isolated environment of historical data. One get's to do this from a jupyter environment that somebody else set up. One even gets to use very complex algorithms by calling model.fit() followed by model.predict(). Lot's of charts are made, metrics are compared and maybe a model is pushed to production.

This is in stark contrast with businesses. Businesses are not confronted with problems that are in isolation. Businesses instead have dynamic situations that consist of complex systems of changing problems that interact with each other. To repeat what is said here; I call such situations messes. Problems are abstractions extracted from messes by analysis; they are to messes 'as atoms are to tables and chairs. We experience messes, tables, and chairs; not problems and atoms.
This is especially true when we consider that the world is a moving target. Optimality is usually of short duration and this is especially true if the consequences of the algorithm aren't too well understood (who knows what happens when we call .fit() or .predict() given enough columns) or if the algorithm can't be changed easily.
It get's worse. The type of model deployed in our field implies a particular paradigm of problem solving. It consists of two parts: predicting the future and making a decision based on this. The effectiveness here depends on how well we can predict the future as well as our ability to act on it. The fact that you can predict something (churn, the weather) does not mean that you can act on it. The fact that you can act on it does not mean that it is predictable.
If we can make good decisions based on predictions then we have another problem: we will cause a shift in the world. This might be great for the short run but it will render our future predictions futile. If we don't see a backlash in predictive power then our algorithm might cause a way worse problem: self fulfilling prophecies.

This algorithmic attitude towards problem solving often leaves business users furiated. Algorithms don't try to understand the underlying system when we call fit().predict(). Objectivity is hard to guarantee unless we understand the system very well. If we understand the system and the objective very well, why do we even bother modelling with black boxes? If we don't understand the objective, how can we be optimal?
The Real Issues
We need to be careful. Stakeholders who are not in our filter bubble will get angry about the misalignment between the hype and the deliveries of our data science field.
Let's be honest.
- Was the real issue in 2016 the fact that we weren't using ApacheSpark[tm]?
- Was the real issue in 2018 the fact that we're not using DeepLearning[tm]?
- Is the real issue in 2019 going to be the fact that we're not using AutoML?
Or is the problem that we don't understand the problem we're trying to solve?
- Do you talk with the end-users? Does this person care about the latest tech or the MSE metrics?
- Do you regularly drink coffee with the working folks down the factory floor? Do you understand what their actual problem is?
- Do you understand that a business is more like a mess than a convenient isolated notebook environment?
If we want this field to survive a winter (or an economic downturn) it might help if the field gets better at recognising that we need to worry less about the algorithm and more about it's application in a system. To do this we need more than mere "data scientists". We need engineers, managers, user interface designers, web programmers, domain experts and people who can come up with ways to improve a business by thinking creatively.
The future of our applied field is not in our new algorithms. It is in remembering all the old things we used to do with algorithms before there was hype.
Conclusion
I recently read an old paper and it caused me to write this document. It was written in an era when data science didn't exist because operation research did. This field was in a similar hype: amazing things could be done with computers and every process in the world was on the brink of optimisation. Yet the paper was a bit gloomy. The title:
the future of operational research is past
Imagine my surprise when I read the paper, written in 1979 by Russel L. Ackhoff, as if it was written about my field today. All arguments I've written here are modern translations from the article which can be found here.
If the article doesn't convince you enough, you might enjoy this delight of a video instead. I would've liked to have known Mr. Ackhoff, I like to think we would've gotten along quite well.